
A large number of organizations are already using Snowflake and dbt, the open source data transformation workflow maintained by dbt Labs, together in production. Python is the latest frontier in our collaboration. This article describes some of what’s made possible by dbt and Snowpark for Python (in public preview).
The problem at hand
Buildingdata applications (inclusive of visualization, machine learning (ML) apps, internal/external business apps, and monetizable data assets) has traditionally required teams to export data out of their analytical store due to a language/tooling preference or limitations of SQL. While users get access to bespoke tooling, improved productivity, and well-documented design patterns for individual personas and scenarios, it also created a situation of:
- More data silos introduced by different tools and processes in the mix
- Increased maintenance and operating costs because of complicated architecture
- Increased security risks introduced by data movement
But what if this wasn’t the case? What if there was a way to address the challenges without sacrificing the advantages?
Introducing our players
In order to solve the problem at hand, we need to examine who are the key players most affected:
- An analytics engineer who may occasionally reach for the Python wrench, for example, using a popular fuzzy string matching library vs. rolling your own implementation in SQL (keep reading, demo below).
- A Python-preferring data scientist and ML engineer deploying ML capabilities (featurization, scoring, training) who is expected to have SQL skills in order to access the enriched, transformed, trusted data from Snowflake.
These players haven’t been properly equipped in the past. When our analytics engineer tries to use Python, they are faced with the challenge of having two data processes to manage. On the flip side, the data scientist and ML engineer don’t easily collaborate with the analytics engineer, who has already transformed the data into the data cloud, which means duplicating existing work.
But what if I told you that Snowflake and dbt Labs can help with this conundrum, and deliver data products with improved productivity, without the issues we described earlier?
Enter Snowpark!
Snowpark is a data programmability framework to explore and transform your organization’s data and leverages Snowflake for data processing, while employing all the benefits that come along with it, such as enterprise-grade governance and security, near-zero infrastructure maintenance, and monetization opportunities.
Snowpark for Python recently became available for public preview, and the use cases it enables are almost limitless, especially for data scientists and ML engineers—from feature engineering to training to serving batch inference.
But what exactly comprises Snowpark for Python? Watch this video for a helpful explanation, which is illustrated in the image below. Hint:*
- A client-side API to allow users to write Spark-like Python code
- Custom Python Functions and Objects support that can run Python libraries available through the Anaconda integration
- Stored Procedure support providing additional capabilities for compute pushdown
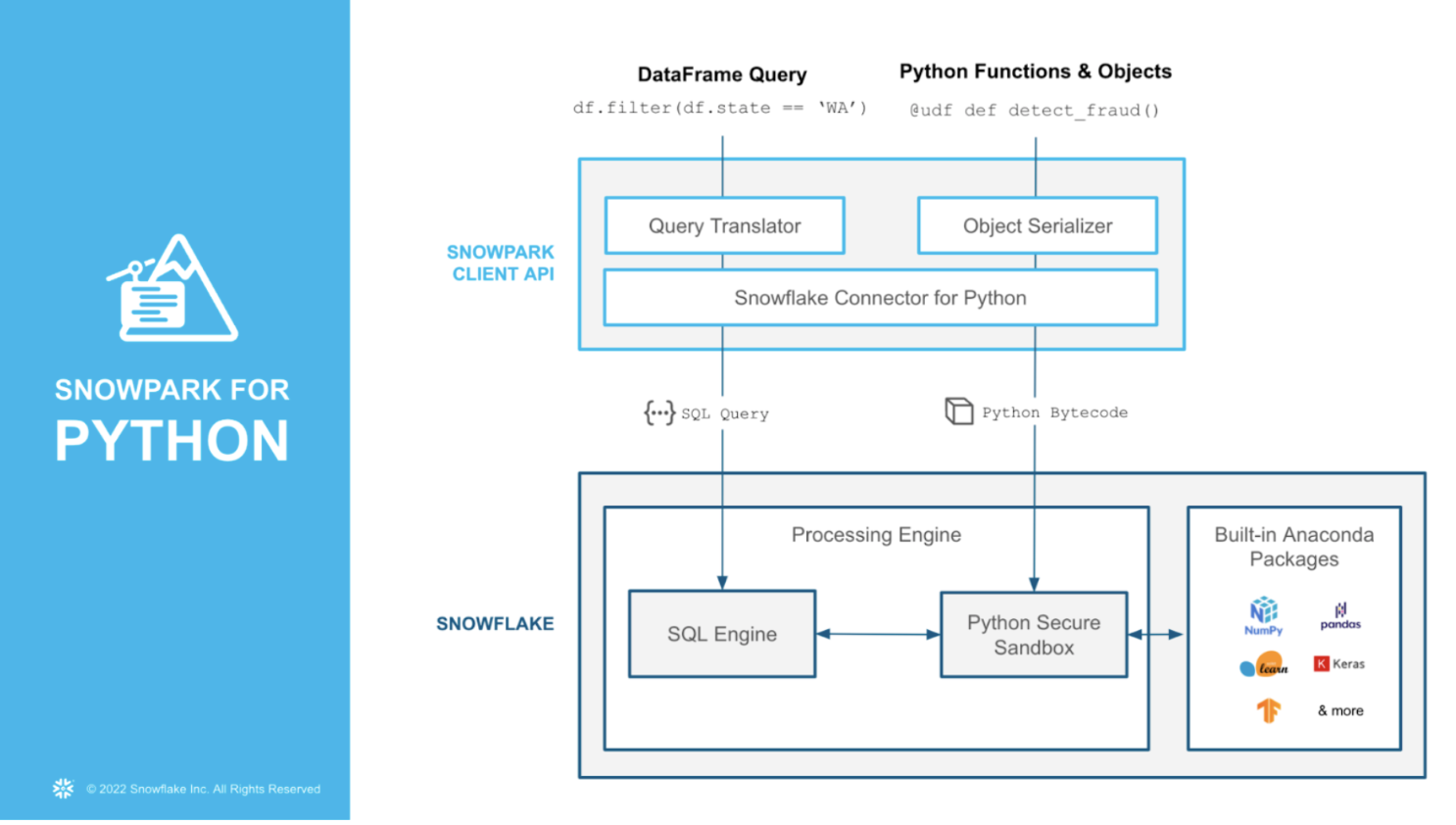
Organizations across industries are putting their data to use, leveraging Snowpark for Python for data science and ML workloads, and solving a number of unique business use cases.

Now, as awesome as Snowpark for Python itself is, its usefulness gets boosted when partners like dbt leverage Snowpark to allow data teams to unify data pipelines for both analytics and ML use cases. In fact, dbt Core’s most asked-for feature was support for Python models in the DAG.
Enter dbt Python models
As dbt Labs CEO Tristan Handy notes in his recent post, Polyglot Pipelines: Why dbt and Python Were Always Meant to Be:
[In July 2017] I wrote ‘we’re excited to support languages beyond SQL once they meet the same bar for user experience that SQL provides today.’And over the past five years, that’s happened.
dbt-labs/new-python-wrench-demo serves to illustrate that Python has arrived with a great user experience. The made-up data, from a fictional “fruit purchasing” app, was created to illustrate a sample use case of when fuzzy string matching can be useful for an analytics engineer. Below are two video walkthroughs of the background, business problem, and code. If you already have a Snowflake account and a dbt project, you can also run this code today. Be sure to open an issue on the repo if you run into trouble.
Taking the next step
If you’re interested in diving deeper into how to get the most out of dbt and Snowpark, then you won’t want to miss dbt’s Coalesce Conference 2022, starting October 17 in New Orleans (as well as virtually.) Expect to see talks such as this one, in which Eda and Venkatesh, Snowflake Partner Sales Engineers, explore how Snowpark further enhances a dbt + Snowflake development experience by supporting new workloads.
If you’d prefer to sink your teeth into something immediately, then the “Getting Started with Snowpark Python” hands-on guide and Eda’s blog post taking a first look at dbt Python models on Snowpark are fantastic resources.
All of this is just scratching the surface of the value created by dbt and Snowpark with Python. Where does it ultimately lead? Toward a future with fewer silos between the people working on analytics workflows and the people working on data science workflows—and we couldn’t be more excited for it.


{kind=link}