
Snowpark for Python GA and Snowpark-optimized warehouses in public preview
As data science and machine learning adoption has grown over the last few years, Python is catching up to SQL in popularity within the world of data processing. SQL and Python are both powerful on their own, but their value in modern analytics is highest when they work together. This was a key motivator for us at Snowflake to build Snowpark for Python to help modern analytics, data engineering, data developers, and data science teams generate insights without complex infrastructure management for separate languages.
Today we’re excited to announce that Snowpark for Python is now in general availability, making all three Snowpark languages ready for production workloads! For Python, this milestone brings production-level support for a variety of programming contracts and even more pre-installed open source packages such as Prophet’s forecasting library, h3-Py library for geospatial analytics, and others.
 Snowpark for Python building blocks now in general availability.
Snowpark for Python building blocks now in general availability.
Snowpark for Python building blocks empower the growing Python community of data scientists, data engineers, and developers to build secure and scalable data pipelines and machine learning (ML) workflows directly within Snowflake—taking advantage of Snowflake’s performance, elasticity, and security benefits, which are critical for production workloads.
Along with Snowpark for Python, we are also announcing the public preview of Snowpark-optimized warehouses. Each node of this new warehouse option provides 16x the memory and 10x the cache compared to a standard warehouse, thereby unlocking ML training inside Snowflake for large data sets. Data scientists and other data teams can now further streamline ML pipelines by having compute infrastructure that can effortlessly execute memory-intensive operations such as statistical analysis, feature engineering transformations, model training, and inference within Snowflake at scale. Snowpark-optimized warehouses come with all of the features and capabilities of virtual warehouses including a fully managed experience, elasticity, high-availability, and built-in security properties.
Tip: You can continue to run Snowpark workloads in standard warehouses if they do not require the additional resources enabled by Snowpark-optimized warehouses. For example, to get the most cost-effective processing, without having to stand up separate environments or copy data across clusters, your ML workflow could look something like this:
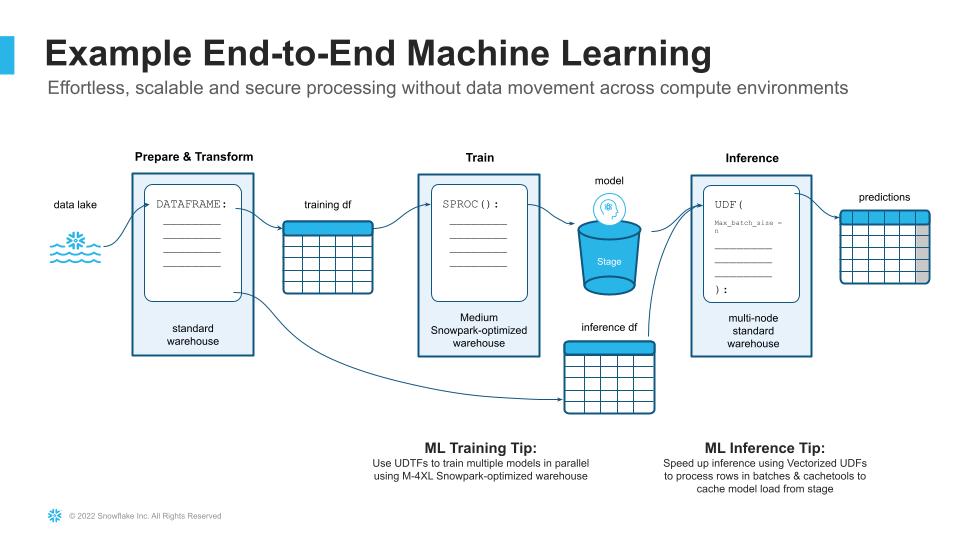 Example of end-to-end ML in Snowflake leveraging Snowpark and various warehouse options.
Example of end-to-end ML in Snowflake leveraging Snowpark and various warehouse options.
To learn how to get the most out of Snowpark and Snowpark-optimized warehouses for ML, be sure to check out the What’s New: Data Science & ML recorded session from Snowday.
Real customer success stories
Using Snowpark’s rich set of functionality, thousands of customers and partners have deployed value-generating solutions for a wide array of tasks. For example, there are many customers using Snowpark to identify potential data quality issues and perform data validation tasks; others are using Snowpark to parse, transform, and load structured, semi-structured, and unstructured data as part of their data engineering pipelines; and many more are putting Snowpark at the heart of their ML stack.
Don’t just take our word for it—check out how Snowpark developers are driving value in their organizations:
Feature engineering that effortlessly scales from development to production
Sophos protects users online with a suite of cybersecurity products. Using the Snowflake Data Cloud, Sophos AI can quickly increase the accuracy of its ML models by allowing data scientists to process large and complex data sets independent of data engineers. Using Snowpark, data scientists can run both Python scripts and SQL without having to move data across environments or spending cycles recoding transformations from development to production, significantly increasing the pace of innovation to better protect its customers from cyberattacks.
Watch Konstantin Berlin, Head of Artificial Intelligence at Sophos, share the company’s story
Large-scale and secure model training and inference with popular open source libraries
One Fortune 500 commercial and retail bank has been modernizing its data and analytics products by shifting from an on-prem Hadoop ecosystem to Snowflake. As part of this journey, the data science team also needed a platform that could meet their growing need for ML use cases. Using XGBoost, available through the Anaconda integration, and Snowpark-optimized warehouses, this Fortune 500 bank was able to securely and effortlessly train a model with a 300M-row data set within minutes, without the need to move data or manage additional infrastructure.
Check out this XGBoost demo of 200 models training in parallel in 10 minutes using UDTFs:
Scalable workflow that provides analysts and BI engineers with self-service metrics
NerdWallet is a personal finance website and app that provides consumers with trustworthy information about financial products. As part of its data-driven mission to enable its business-focused teams to make data decisions quickly and independently, the Data Engineering team developed a scalable workflow using Snowpark and Apache Airflow that empowers the Analytics teams to define, publish, and update their domain-specific data sets directly in Snowflake.
Check out this blog post featuring sample code from Adam Bayrami, Staff Software Engineer at NerdWallet, and his team
Effortless execution of custom Python logic, including pre-trained deep learning models for better thread detection
Anvilogic is a modern security operations platform that unifies and automates threat detection, hunting, triage and incident response. To detect malicious attacks using text classification, Anvilogic’s data science team leverages the Snowpark API to prepare (e.g., create text substrings as features) millions of logs for training. Once the deep learning models are trained, its ML team can easily conduct complex inference computation in Snowflake using Snowpark for Python UDFs.
Read more about Anvilogic’s approach in this blog post from Michael Hart, Principle Data Scientist
Modernizing data processing infrastructure for large-scale data pipelines
IQVIA provides advanced analytics, technology solutions, and clinical research services to the life sciences industry. Its legacy Hive data warehouse and pipeline processing with Spark was limiting the speed at which the company could derive insights and value. Using Snowflake as its data lake and replacing a Spark/Scala rule engine to Snowpark gave IQVIA 2x the performance at 1/3 of the cost.
Hear from Suhas Joshi, Sr. Director of Clinical Data Analytics at IQVIA, in this webinar
In addition to customers, our Snowpark Accelerated partners have been building better experiences for their customers by developing interfaces that leverage Snowflake’s elastic engine for secure processing of both Python and SQL. Take, for example, the Dataiku MLOps platform, which accelerates the speed at which projects go from pilot to production; dbt’s Python models, which will now help you unify your Python and SQL transformation logic in production; or Hex, which through Snowpark enables data practitioners to have a language-agnostic notebook interface.
For more examples of how to use Snowpark for Python, check out these blog posts from Jim Gradwell, Head of Engineering & Machine Learning, who is building a serverless architecture for HyperFinity’s data science platform, as well as from Snowflake Superhero James Weakley, who shows you how to generate synthetic data with Snowpark. Also be sure to follow Dash Desai, Snowpark Sr. Tech Evangelist, who is always sharing cool tricks and best practices on how to use Snowpark—including how you can contribute to the open source client library.
What’s next?
General availability of Snowpark for Python is just the beginning. Since Snowflake first began inviting early adopters to work with Snowpark for Python, we’ve been actively expanding our functionality based on community feedback, in particular, our commitment to making open source innovation seamless and secure.
Through the Snowflake ideas board, in partnership with Anaconda, we evaluate community requests and continue to add packages to the existing repository of more than 2,000 packages available in the Snowflake channel. A few additions since public preview worth highlighting include prophet, pynomaly, datasketch, h3-py, gensim, email_validator, pydf2, tzdataand the list could go on.

In addition to more packages, which everyone loves, we are also looking to:
- Add support for Python 3.9 and higher
- Offer user-defined aggregate functions (UDAGs), which let you take multiple rows at once and return a single aggregated value as a result
- Give organizations the ability to have more granular package access controls
- Add External access so that your functions can securely leverage external services in your workflow, including calling APIs, loading external reference data, and more
Related to Snowpark, we also have a raft of features announced in private preview at Snowday, including Python worksheets, logging support, and support for dynamic unstructured file processing, Streamlit in Snowflake integration, and much more, so stay tuned!
Resources
In addition to the Snowpark for Python get started guide, the Snowpark+Streamlit lab and the Advanced ML with Snowpark guide, which have been updated to show you how to use SProcs (in the get started) and UDTFs (in the advanced) for ML training in Snowflake, check out the upcoming session on DevOps and git-flow with Snowpark at BUILD.
And if you have any questions, be sure to ask the community in the Snowflake Forums.
Let’s go build!
Forward-Looking Statements
This post contains express and implied forward-looking statements, including statements regarding (i) Snowflake’s business strategy, (ii) Snowflake’s products, services, and technology offerings, including those that are under development or not generally available, (iii) market growth, trends, and competitive considerations, and (iv) the integration, interoperability, and availability of Snowflake’s products with and on third-party platforms. These forward-looking statements are subject to a number of risks, uncertainties and assumptions, including those described under the heading “Risk Factors” and elsewhere in the Quarterly Reports on Form 10-Q and Annual Reports of Form 10-K that Snowflake files with the Securities and Exchange Commission. In light of these risks, uncertainties, and assumptions, actual results could differ materially and adversely from those anticipated or implied in the forward-looking statements. As a result, you should not rely on any forward-looking statements as predictions of future events.
© 2022 Snowflake Inc. All rights reserved. Snowflake, the Snowflake logo, and all other Snowflake product, feature and service names mentioned herein are registered trademarks or trademarks of Snowflake Inc. in the United States and other countries. All other brand names or logos mentioned or used herein are for identification purposes only and may be the trademarks of their respective holder(s). Snowflake may not be associated with, or be sponsored or endorsed by, any such holder(s).

{kind=link}