
 |
Last year, Amazon S3 Glacier celebrated its tenth anniversary. Amazon S3 Glacier is the leader in cloud cold storage, and I wrote about its innovations over the last decade.
The Amazon S3 Glacier storage classes provide you with long-term, secure, and durable storage options to optimally archive your data at the lowest cost. The Amazon S3 Glacier storage classes (Amazon S3 Glacier Instant Retrieval, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive) are purpose-built for colder data, providing you with retrieval flexibility from milliseconds to days, in addition to the ability to store archive data for as low as $1 per terabyte per month.
Many customers tell us that they are keeping their data for longer periods of time because they recognize its future value potential, and that they are already monetizing subsets of their archival data, or plan to use large sets of their archive data in the future. Modern data archiving is not only about optimizing storage costs for cold data; it’s also about setting up mechanisms so that when you need to put that data to work for your business, you can access it as quickly as your business requirements demand.
In 2022, AWS customers restored over 32 billion objects from Amazon S3 Glacier. Customers need to retrieve archived objects quickly when transcoding media, restoring operational backups, training machine learning (ML) models, or analyzing historical data. While customers using S3 Glacier Instant Retrieval can access their data in just milliseconds, S3 Glacier Flexible Retrieval is lower cost and provides three retrieval options: expedited retrievals in 1–5 minutes, standard retrievals in 3–5 hours, and free bulk retrievals in 5–12 hours. S3 Glacier Deep Archive is our lowest cost storage class and provides data retrieval within 12 hours using the standard retrieval option or 48 hours using the bulk retrieval option.
In November 2022, Amazon S3 Glacier improved restore throughput by up to 10 times at no additional cost when retrieving large volumes of archived data in S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive. With Amazon S3 Batch Operations, you can automatically initiate requests at a faster rate, allowing you to restore billions of objects containing petabytes of data.
To continue the decade-long trend of cold storage innovation, we are announcing today the general availability of faster Standard retrievals from S3 Glacier Flexible Retrieval by up to 85 percent, at no additional cost. Faster data restores automatically apply to the Standard retrieval tier when using S3 Batch Operations.
Using S3 Batch Operations, you can restore archived data at scale by providing a manifest of objects to be retrieved and specifying a retrieval tier. With S3 Batch Operations, restores in the Standard retrieval tier now typically begin to return objects to you within minutes, down from 3–5 hours, so you can easily speed up your data restores from archive.
Additionally, S3 Batch Operations improves overall restore throughput by applying new performance optimizations to your jobs. As a result, you can restore your data faster and process restored objects sooner. Processing restored data in parallel with ongoing restores helps you accelerate data workflows and quickly respond to business needs.
Getting Started with Faster Standard Retrievals from S3 Glacier Flexible Retrieval
To restore archived data with this performance improvement, you can use S3 Batch Operations to perform both large- and small-scale batch operations on S3 objects. S3 Batch Operations can perform a single operation on lists of S3 objects that you specify. You can use S3 Batch Operations through the AWS Management Console, AWS Command Line Interface (AWS CLI), SDKs, or REST API.
To create a batch job, choose Batch Operations on the left navigation pane of the Amazon S3 console and choose Create job. You can select one of the manifest formats, a list of S3 objects that contains object keys that you want to retrieve. If your manifest format is a CSV file, each row in the file must include the bucket name, object key, and, optionally, the object version.

In the next step, choose the operation that you want to perform on all objects listed in the manifest. The Restore operation initiates restore requests for archived objects on a list of S3 objects that you specify. Using a restore operation results in a restore request for every object that is specified in the manifest.
When you restore with the Standard retrieval tier from the S3 Glacier Flexible Retrieval storage class, you automatically get faster retrievals.
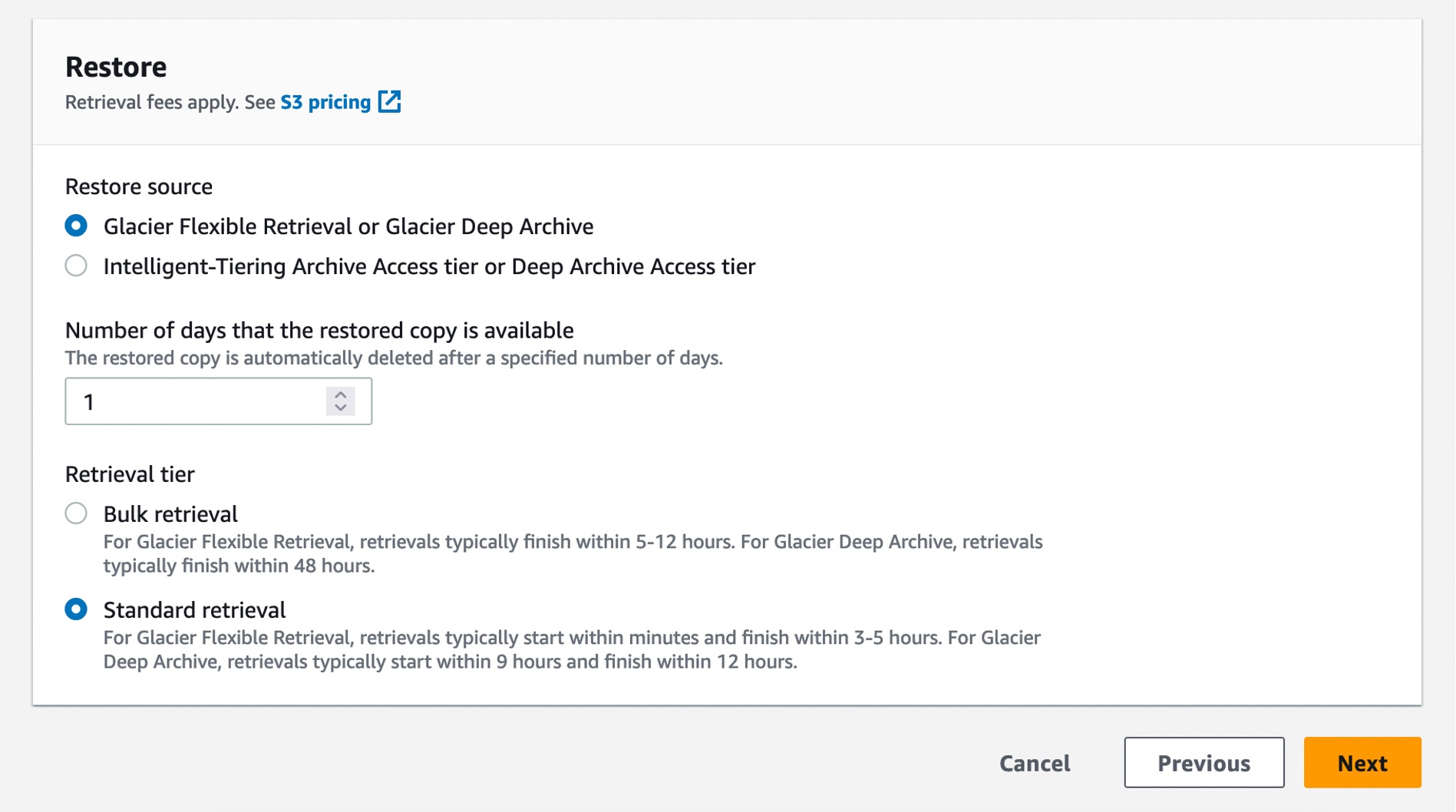
You can also create a restore job with S3InitiateRestoreObject job using the AWS CLI:
$aws s3control create-job –region us-east-1 –account-id 123456789012 –operation ‘{“S3InitiateRestoreObject”: { “ExpirationInDays”: 1, “GlacierJobTier”:”STANDARD”} }’ –report ‘{“Bucket”:”arn:aws:s3:::reports-bucket “,”Prefix”:”batch-op-restore-job”, “Format”:” S3BatchOperations_CSV_20180820″,”Enabled”:true,”ReportScope”:”FailedTasksOnly”}’ –manifest ‘{“Spec”:{“Format”:”S3BatchOperations_CSV_20180820″, “Fields”:[“Bucket”,”Key”]},”Location”:{“ObjectArn”:”arn:aws:s3:::inventory-bucket/inventory_for_restore.csv”, “ETag”:”
You can then check the status of the job submission of the requests by running the following CLI command:
$ aws s3control describe-job –region us-east-1 –account-id 123456789012 –job-id
You can view and update the job status, add notifications and logging, track job failures, and generate completion reports. S3 Batch Operations job activity is recorded as events in AWS CloudTrail. For tracking job events, you can create a custom rule in Amazon EventBridge and send these events to the target notification resource of your choice, such as Amazon Simple Notification Service (Amazon SNS).
When you create an S3 Batch Operations job, you can also request a completion report for all tasks or just for failed tasks. The completion report contains additional information for each task, including the object key name and version, status, error codes, and descriptions of any errors.
For more information, see Tracking job status and completion reports in the Amazon S3 User Guide.
Here is the result of a sample retrieval job with 250 objects, each sized 100 MB. As you can see from the Previous restore performance line (blue line at the right), these restores would typically finish in 3–5 hours using Standard retrievals. Now, when you use Standard retrievals with S3 Batch Operations, your job typically starts within minutes, as shown in the Improved restore performance line (orange line at the left), improving data restore time by up to 85 percent.

To learn more, see Restoring archived objects at scale from the Amazon S3 Glacier storage classes on the AWS Storage Blog and Restoring an archived object in the Amazon S3 User Guide.
Additionally, check out this blog to learn how you can reduce recovery time and optimize storage costs with faster restores from Amazon S3 Glacier storage classes and Commvault.
Now Available
Faster standard retrievals for Amazon S3 Glacier Flexible Retrieval are now available in all AWS Regions, including the AWS GovCloud (US) Regions and China Regions. This performance improvement is available to you at no additional cost. You are charged for S3 Batch Operations and data retrievals. For more information, see the S3 pricing page.
 Lastly, we published a new ebook titled “Maximize the value of cold storage with Amazon S3 Glacier“. Read this ebook to learn how Amazon S3 Glacier is helping organizations of all sizes and from all industries transform their data archiving to unlock business value, increase agility, and save on storage costs.
Lastly, we published a new ebook titled “Maximize the value of cold storage with Amazon S3 Glacier“. Read this ebook to learn how Amazon S3 Glacier is helping organizations of all sizes and from all industries transform their data archiving to unlock business value, increase agility, and save on storage costs.
To learn more, visit the S3 Glacier storage classes page and getting started guide, and send feedback to AWS re:Post for S3 Glacier or through your usual AWS Support contacts.
I’m really excited for you to start using this new feature, and I look forward to hearing about even more ways you are reinventing your business with archive data.
— Channy
