
During the development of JFrog Xray’s Secrets Detection, we tested its capabilities by scanning more than eight million artifacts in popular open-source package registries. Similarly, for JFrog Xray’s new Container Contextual Analysis feature, we again tested our detection in a large-scale, real-world use case, both for eliminating bugs and for assessing the real-world viability of our current solution.
However, unlike the surprising results we got in our Secrets Detection research (we discovered many more active access tokens than we bargained for), the results of our scans of Docker Hub container images were in line with what we were seeing, as security engineers, for many years now.
Namely, when the metric for a vulnerable system is simply “package X is installed,” we expect most security alerts to be false positives. And this was exactly the case for the CVEs we detected in container images on Docker Hub.
In this post we will detail our research methodology and findings and offer some advice for developers and security professionals looking to reduce the volume of CVE false positives.
Exploitable vs. ‘vulnerable package is installed’
Before diving in, let’s briefly look at some example vulnerabilities to understand cases where a CVE report could be considered a false positive, even when a vulnerable component exists.
This is not an exhaustive list by any means, but it does cover the most prominent causes of CVE false positives.
Library vulnerabilities
 JFrog
JFrog
Does the fact that a vulnerable version of Lodash is installed guarantee a vulnerable system?
No. By definition, we cannot determine whether a CVE in a library is exploitable simply by noting that the library is installed. This is because a library is not a runnable entity; there must be some other code in the system that uses the library in a vulnerable manner.
In the example above, even if Lodash is installed, the system may not be vulnerable. There must be some code that calls the vulnerable function, in this case template(), from the vulnerable Lodash library. In most cases, there are even additional requirements, such as that one of the arguments passed to template() would be attacker-controlled.
Other code-related prerequisites may include:
- Whether a mitigating function is called before the vulnerable function.
- Whether specific arguments of the vulnerable function are set to specific vulnerable values.
Service configuration
 JFrog
JFrog
Does the fact that a vulnerable version of Cassandra is installed guarantee a vulnerable system?
No. In most modern service vulnerabilities (especially ones with severe impact) the vulnerability only manifests in non-default configurations of the service. This is because the default and sane configuration is often tested the most, either by the developers themselves or simply by the real-world users of the service.
In the example above, to achieve remote code execution (RCE), the Cassandra service must be configured with three non-default configuration flags (one of them being quite rare).
Other configuration-related prerequisites may include:
- Whether the component is being run with specific command-line arguments or environment variables.
- Whether the vulnerable component was compiled with specific build flags.
Running environment
 JFrog
JFrog
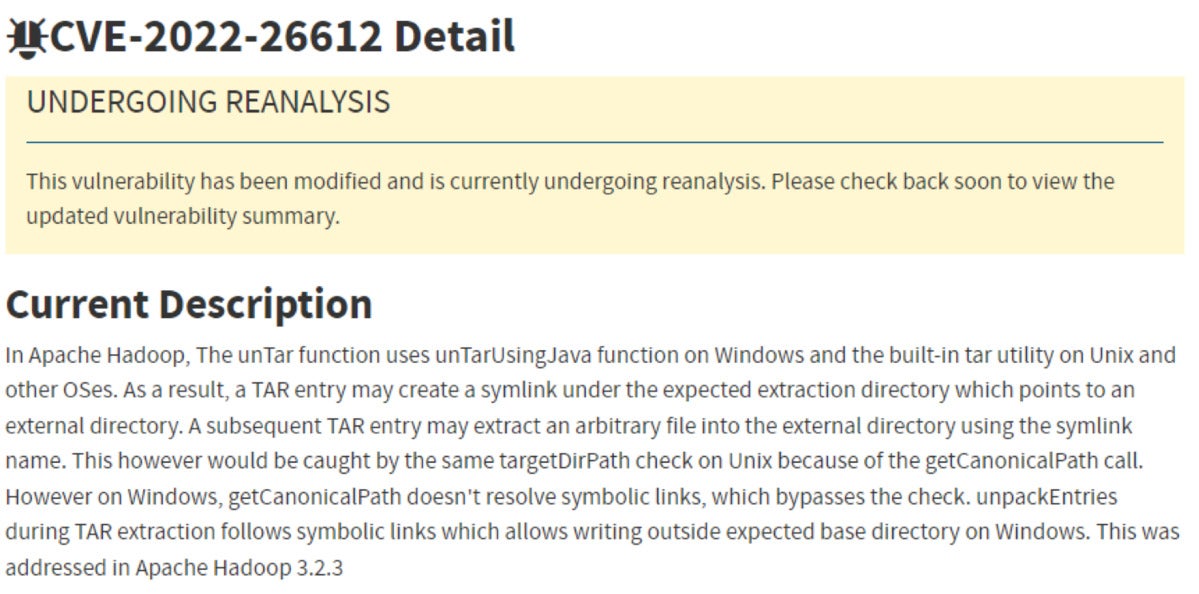
Does the fact that a vulnerable version of Apache Hadoop is installed guarantee a vulnerable system?
No. In the example above, the vulnerability only manifests in a Microsoft Windows environment. Therefore if the vulnerable component is installed in a Linux environment, it cannot be exploited.
Other environment-related prerequisites may include:
- Whether the vulnerable component is running in a specific distribution (e.g. Debian)
- Whether the vulnerable component is compiled for a specific architecture (e.g. 32-bit Arm).
- Whether a firewall blocks communication to the vulnerable service.
Our research methodology
In this research, we set out to find what percentage of vulnerability reports actually indicate that the vulnerability is exploitable, when considering two reporting techniques:
- Naive. The vulnerability is reported whenever a vulnerable component is installed in the relevant (vulnerable) version range. This is how almost all SCA tools work today.
- Context-sensitive. The vulnerability is only reported (or said to be applicable) if the context of the image indicates vulnerable usage of the component. This takes into account factors that were discussed in the previous section (code prerequisites, configuration prerequisites, running environment).
We are interested in testing the above in common real-world environments, and performing this test on as many environments as possible.
 JFrog
JFrog
We realized that looking at Docker Hub’s top “community” images should satisfy both requests, for two reasons:
- These images are used extremely frequently. For example, the top 25 images currently have more than 1 billion downloads.
- Community images usually contain both an interesting component and the code that uses the component to some end, which provides a realistic context. This is unlike “official” Docker images that usually contain standalone components that are left unused and in their default configuration. For example, an Nginx web server by itself with default configuration would probably not be susceptible to any major CVE, but it does not provide a realistic scenario.
Based on these factors, we arrived at the following methodology:
- Pull Docker Hub’s top 200 community images, in their “latest” tag.
- Gather from these images the top 10 most “popular” CVEs (sorted by CVE occurrence across all images).
- Run our contextual analysis on all 200 images.
- Calculate the percentage of the naive method false positive rate, by dividing “non-applicable occurrences” by “total occurrences” for each of the top 10 CVEs.
What were the top 10 CVEs?
And so we scanned Docker Hub’s top 200 community images. The table below lists the CVEs that appeared in the highest number of images.
|
CVE ID |
CVSS |
Short description |
|
CVE-2022-37434 |
9.8 |
zlib through 1.2.12 has a heap-based buffer over-read or buffer overflow in inflate(). Only applications that call inflateGetHeader are affected. |
|
CVE-2022-29458 |
7.1 |
ncurses 6.3 has an out-of-bounds read and segmentation violation in convert_strings() |
|
CVE-2021-39537 |
8.8 |
ncurses through v6.2 nc_captoinfo() has a heap-based buffer overflow |
|
CVE-2022-30636 |
N/A |
Golang x/crypto/acme/autocert: httpTokenCacheKey allows limited directory traversal on Windows |
|
CVE-2022-27664 |
7.5 |
Golang net/http before 1.18.6 DoS because an HTTP/2 connection can hang |
|
CVE-2022-32189 |
7.5 |
Golang math/big before 1.17.13 Float.GobDecode and Rat.GobDecode DoS due to panic |
|
CVE-2022-28131 |
7.5 |
Golang encoding/xml before 1.17.12 Decoder.Skip DoS due to stack exhaustion |
|
CVE-2022-30630 |
7.5 |
Golang io/fs before 1.17.12 Glob DoS due to uncontrolled recursion |
|
CVE-2022-30631 |
7.5 |
Golang compress/gzip before 1.17.12 Reader.Read DoS due to uncontrolled recursion |
|
CVE-2022-30632 |
7.5 |
Golang path/filepath before 1.17.12 Glob DoS due to stack exhaustion |
How many CVEs were actually exploitable?
We deliberately chose to run the contextual scanners on their most conservative setting — more on that in the next section.
The contextual scanner for each CVE was defined as described in the table below.
|
CVE ID |
Contextual scanner |
|
CVE-2022-37434 |
Check for 1st-party code that calls “inflateGetHeader” and “inflate” |
|
CVE-2022-29458 |
Check for invocations of the ncurses “tic” CLI utility |
|
CVE-2021-39537 |
Check for invocations of the ncurses “cap2info” CLI utility |
|
CVE-2022-30636 |
Check for Windows OS + 1st-party code that calls “autocert.NewListener” or references “autocert.DirCache” |
|
CVE-2022-27664 |
Check for 1st-party code that calls “ListenAndServeTLS” (HTTP/2 is only available over TLS) |
|
CVE-2022-32189 |
Check for 1st-party code that calls “Rat.GobDecode” or “Float.GobDecode” |
|
CVE-2022-28131 |
Check for 1st-party code that calls “Decoder.Skip” |
|
CVE-2022-30630 |
Check for 1st-party code that calls “fs.Glob” with non-constant input |
|
CVE-2022-30631 |
Check for 1st-party code that calls “gzip.Reader.Read” |
|
CVE-2022-30632 |
Check for 1st-party code that calls “filepath.Glob” with non-constant input |
–
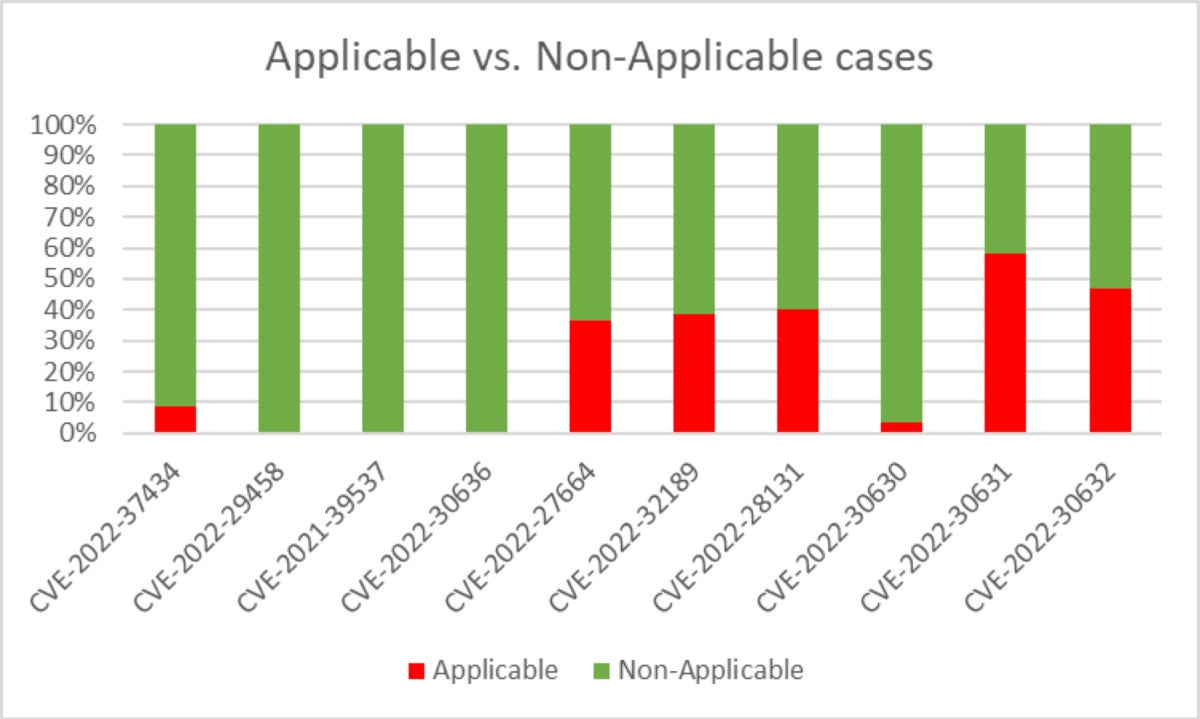
Running the contextual scanners on all 200 images gave us the following results, per CVE.
 JFrog
JFrog
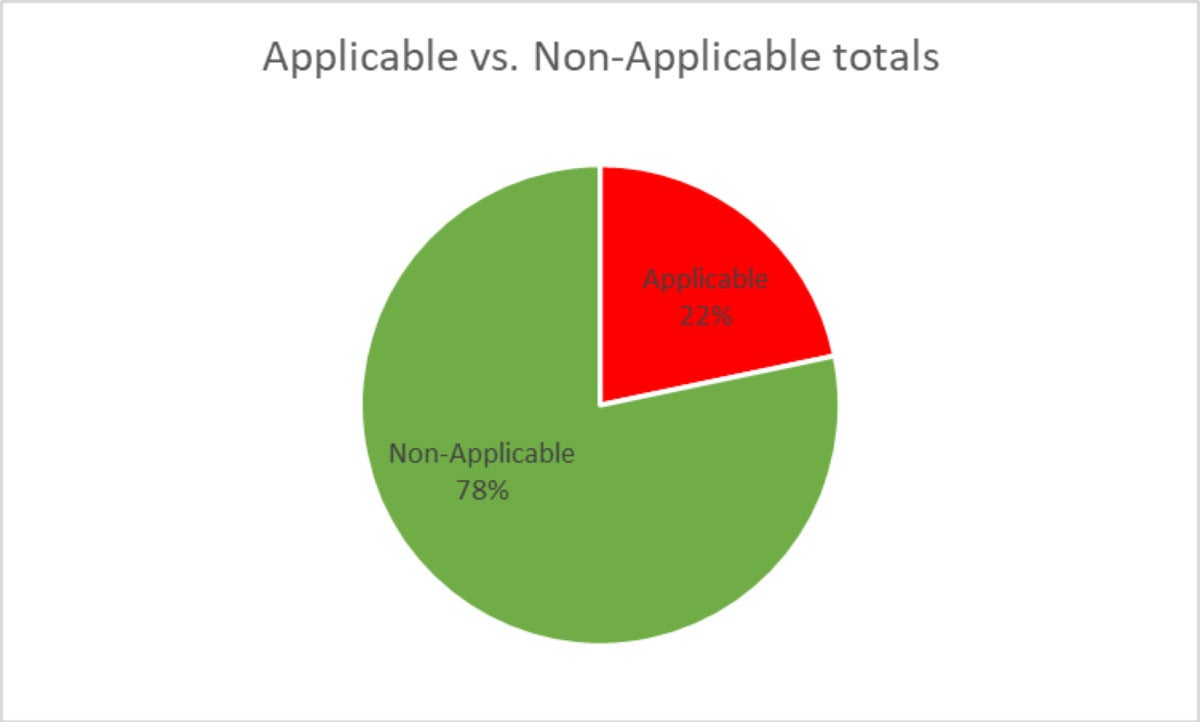
And when we tallied the results of all top 10 CVEs together, here’s what we discovered:
 JFrog
JFrog
78% of the CVE cases were found to be non-applicable!
Looking at the current limits of contextual analysis
Let’s examine CVE-2022-30631, which had an exceptionally high applicability rate.
CVE-2022-30631 was the only one that crossed 50% applicability. In layman’s terms, the prerequisite for this CVE to be exploitable is “Golang is used to extract an attacker-controlled gzip archive.” In reality, the scanner will alert if first-party Golang code tries to extract any gzip archive. This is because guaranteeing whether a file is attacker-controlled is a very hard task, due to the multitude of possible sources affecting the file.
When trying to determine whether a variable comes from constant input or external/attacker input, this can be achieved for example via data flow analysis. Data flow analysis is performed by some of our scanners, detecting CVE-2022-30630, for example, which had a much lower applicability rate.
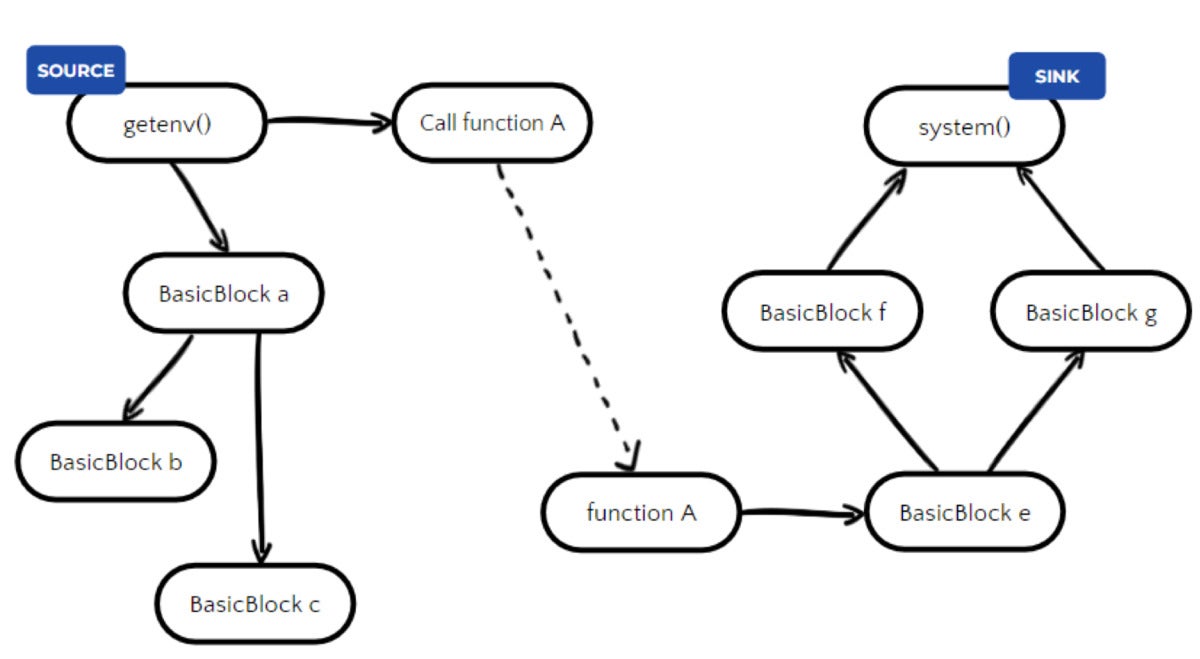 JFrog
JFrog
But when dealing with files, even if the function’s file path argument is constant, there is no guarantee that the file is not attacker-controlled, and vice versa. Therefore, we expect the real-world applicability of this CVE to be even lower.
Why 78% is actually a conservative number
From the example above, we can see that some CVEs may have an exaggerated applicability rate, meaning the real-world applicability may be even lower. It is important to discuss why (in the common case) it still makes sense to run conservative scanners. There are two reasons for this: first, because we prefer false positives to false negative, and second, because of performance considerations.
Preference towards false positives and not false negatives
Every technology has its limitations, and this is doubly true when trying to solve computationally infeasible problems such as “can a certain input be controlled by external sources.” In certain cases (the easier ones), we can make certain assumptions that make the computation of the solution possible with extremely high confidence.
However, in other cases (the harder one), where 100% confidence is not guaranteed, we should do two things:
- Prefer scanners that tend to show false positives (in our case, show results as applicable when in reality they are not). This is done because, in this case, the result will be examined by an engineer and evaluated whether it is really applicable or not. In the opposite case, where the vulnerability would be flagged as non-applicable, the engineer will assume it can be ignored, and thus the vulnerability would be left vulnerable, which is a much more severe scenario.
- Whenever possible, provide the confidence rate and/or the reason for low confidence in a specific finding, so that even applicable results can be prioritized by security/devops engineers.
Performance considerations
A contextual scanner that’s based on data flow analysis (for example, a scanner that tries to determine whether a specific function’s argument is coming from attacker-controlled input or not) will always have an option in its implementation whether to provide more accurate results or to run faster. For example, the most accurate type of contextual scanner must at least:
- Allow for an infinite call depth when trying to build an intra-module data flow graph between an attacker-controlled source and the requested sink.
- Consider inter-module calls when building the data flow graph.
These operations greatly increase the scanner’s run time.
When dealing with a great amount of scanned artifacts per minute (as may be requested from a JFrog Artifactory/Xray instance) we must achieve a delicate balance between the accuracy and the speed of the contextual scanner.
Even when considering the discussed limitations, 78% is still a massive number of vulnerabilities that can be either de-prioritized or ignored. Furthermore, we expect this number to become higher as technology advances and as less “applicable by default” CVEs are discovered.
![Read more about the article How to Cancel NordVPN in 2023 [Easy Step-By-Step Guide]](https://fast4net.com/wp-content/uploads/2023/02/how-to-cancel-nordvpn-in-2023-easy-step-by-step-guide-300x180.png)

{kind=link}