
Snowflake continues to set the standard for data in the cloud by removing the need to perform maintenance tasks on your data platform and giving you the freedom to choose your data model methodology for the cloud. There will be scenarios where you may need to consider transaction isolation, and such a scenario does exist for Data Vault: the common hub table.
This post is number 8 in our “Data Vault Techniques on Snowflake” series:
- Immutable Store, Virtual End Dates
- Snowsight Dashboards for Data Vault
- Point-in-Time Constructs and Join Trees
- Querying Really Big Satellite Tables
- Streams and Tasks on Views
- Conditional Multi-Table INSERT, and Where to Use It
- Row-Access Policies + Multi-Tenancy
- Hub Locking on Snowflake
- Virtual Warehouses and Charge Back

We explored the concept of passive integration in the previous blog post. If we are looking to integrate by and concurrently load to common hub tables, per the business object definition, this is the ideal situation for a Data Vault model. With Snowflake being READ COMMITTED transaction isolation level, how do we guarantee that independent hub table loaders leave the target hub table with the same integrity after the load? Let’s explore how this is done in Snowflake and what this could mean to your Data Vault model.
 Parallel loading and eventual consistency.
Parallel loading and eventual consistency.
As illustrated above, any landed source data is staged and loaded to the modeled hub, link, and satellite tables.
- Satellite tables are single source and are unique by defined parent key, load date, and the descriptive state content.
- Link tables are rarely multi-source and are unique by defined unit of work.
- Hub tables are always multi-source and are unique by business object.
Notice how each source loads to a common hub table in the above example. They must leave the hub table in the same integrity as each hub-loader found it; a unique list of business objects defined by business key, business key collision code, and multi-tenant id.
The problem
The problem is the same as described in blog post 6, Conditional Multi-Table INSERT, and Where to Use It, in which we discussed conditional multi-table inserts. If each thread attempting to load to the same target hub table is executed at the exact same time, due to the nature of READ COMMITTED transaction isolation, each thread views the target table without UNCOMMITTED transactions coming from other threads. See an illustration of this below:
 The problem
The problem
Duplicates break the integrity of the Data Vault model, and you will start to see information marts—and by association, the data structures—start to suffer as well.
The solution
Snowflake does in fact allow for table locking, and the syntax is simple: change the SQL INSERT statement into an SQL MERGE statement and the target hub table defined in the MERGE statement will be locked when it is its turn to update the target table. Of course, this implies that the hub-loader template is changed, and all configured hub-loaders will then use the SQL MERGE INTO statement instead.
 The solution insert into HUB_TABLE select distinct from STAGED stg where not exists (select 1 from HUB_TABLE h where stg.HASH-KEY = h.HASH-KEY) merge into HUB_TABLE h using (select distinct from STAGED) stg on h.HUB_KEY = stg.HUB_KEY when not matched then insert () values ()
The solution insert into HUB_TABLE select distinct from STAGED stg where not exists (select 1 from HUB_TABLE h where stg.HASH-KEY = h.HASH-KEY) merge into HUB_TABLE h using (select distinct from STAGED) stg on h.HUB_KEY = stg.HUB_KEY when not matched then insert () values ()
Three SQL data manipulation language (DML) statements lock Snowflake tables for updates:
- SQL MERGE – Inserts, updates, and deletes values in a table based on values in a second table or a subquery
- SQL UPDATE – Updates specified rows in the target table with new values
- SQL DELETE – Remove rows from a table
In the grand scheme of automation, our earlier animated example can now be updated like this:

Does this approach add latency? Probably, but it should be minor because hub tables typically only process a few condensed records at a time using anti-semi joins. The beauty of this approach is that we did not need to explicitly lock the target table using externally defined semaphores. Instead, Snowflake randomly decides which thread will get processed first, and for hub tables that works just fine!
While you’re there at the hub table…
SQL MERGE statements allow for SQL INSERTs and UPDATEs, offering an opportunity to explore a Data Vault artifact that was previously deprecated, the “last seen date” column in the hub and link table. Because hub and link tables are wafer thin and tend to be short, the number of micro-partitions that make up these tables is very small. Why not allow for SQL UPDATEs to the hub and link table?
Yes, the cost of SQL UPDATEs are expensive operations, but this might also be true for satellite tables where we might see as little as a single descriptive column to hundreds of descriptive columns. SQL UPDATEs are still not recommended here. Let’s update our previous example to show where last-seen-date can be useful:

merge into HUB_TABLE h using (select distinct from STAGED) stg on h. HUB_KEY = stg.HUB_KEY when not matched then insert () values () merge into HUB_TABLE h using (select distinct from STAGED) stg on h. HUB_KEY = stg.HUB_KEY when matched then update set h.LAST = stg.LAST when not matched then insert () values ()
Other Data Vault artifacts
Other certain Data Vault artifacts were developed to track this very information because they are INSERT-ONLY table structures. These are:
- Record Tracking Satellites (RTS) – designed to record every time we see a business object or unit of work.
- Status Tracking Satellites (STS) – designed to track when a business object or unit of work appears, updates, or is deleted in the source if the source is provided as a snapshot.
- Effectivity Satellites (EFS) – combined with a driver key, we track the driver key(s) against the non-driver key(s) of a relationship.
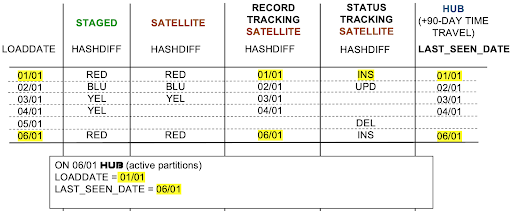 Compare SAT, RTS, STS, HUB last-seen-date.
Compare SAT, RTS, STS, HUB last-seen-date.
Because “last seen date” only records the latest occurrence of the business object or unit-of-work, it is not a reliable source to check the following:
- Source frequency of occurrence as tracked in RTS
- Source deletions as tracked in STS
- Changing relationships when they need to be tracked for the current relationship
Driving key and effectivity
If the data source does not contain a business date tracking the effectivity of the driving entity of the relationship—or if you wish to track effectivity of a different driving entity than that of what is tracked in the data source—then there’s a need for an effectivity satellite. A LAST_SEEN_DATE column in the link table will give you what the current relationship is without needing one of the most complex Data Vault patterns. Let’s explore this further using the following example:
 What you lose if you don’t use EFS.
What you lose if you don’t use EFS.
No matter what the driving key is when utilizing the LAST_SEEN_DATE, you will get the current active relationship for that driving key/relationship. It also does not require that you deploy multiple effectivity satellites for each driving key you want to track on a single link table. However, you will not be able to trace the historical movement of that driving to non-driving key relationship. That is the exclusive realm of the effectivity satellite unless (again) the source system provides this movement.
To lock or not to lock
Always test these scenarios for yourself! The idea behind this technique is to take advantage of what Snowflake technology offers and keep Data Vault automation single purpose.
As quoted from the Zen of Python: “There should be one—and preferably only one—obvious way to do it.”
- A hub loader should load one hub table from a single source file.
- A link loader should load one link table from a single source file.
- A satellite loader should load one satellite table from a single source file.
- There should be one way to do staging of landed content.
Leverage Snowflake technology to ensure you meet your automation goals.
{kind=link}