
Apache Parquet format is one of the more commonly used file formats to support fast data processing. It is column-oriented, open source, and contains metadata, but its schema evolution and great compression ratio are big reasons why Parquet is one of the most popular file formats for analytical workloads in the industry.
So it’s no surprise that Parquet is the file format that customers most often load into Snowflake. As outlined in Best Practices for Data Ingestion with Snowflake: Part 1, batch loading of files in Snowflake is typically accomplished by data loading option COPY command. Coupled with the elasticity that Snowflake has to offer, from a compute standpoint—COPY command can load your data in a highly effective manner. This blog post outlines a couple of alternative ways to accomplish the same outcome by loading Parquet files using an “INSERT as SELECT” pattern and Streams over External Tables.
Many customers enjoy the simplicity of working with Parquet, XML, AVRO, and JSON because of the platform’s unique, native support for these file formats right out of the box. However, the focus of this post is on batch ingestion for Parquet. For other batch, micro-batch, or continuous ingestion patterns, please refer to these best practices.
This blog post provides step-by-step instructions for loading Parquet files to Snowflake tables, using three different approaches:
- Traditional COPY command that most are familiar with
- Using INSERT into SELECT FROM clause
- Using Streams over External Tables
After walking through how to perform these different approaches, I’ll compare results to help you determine which approach makes the most sense for your use case.
Note: I appreciate your trust but encourage you to independently verify my findings by facilitating the three approaches yourselves. Although I provide and compare the results in this post, you can run the SQL commands in your own Snowflake account to calculate performance. Note that as you run these commands in your account—results may vary slightly based on warehouse size—you will incur credit consumption.
Setup
For new learners, Snowflake provides a variety of compute options for loading data. For the purpose of comparing performance in this blog post, I perform each of the three load patterns with warehouses Small through 2XL, but you have the flexibility to choose the warehouse size based on the performance requirements of your own use case.
Step 1: Create an external stage
For the purpose of this post, I will be using Amazon S3 buckets (located in the same region as my Snowflake account) for storing Parquet files in an external stage, but similar instructions are applicable for Google Cloud Storage, Azure Blob Storage, and Azure Data Lake Storage Gen2.
create or replace external stage mysales.public.aws_external_stage storage_integration = s3_int url = ‘s3://mybucket/encrypted_files/’ file_format = (type = parquet);
Step 2: Generate data in Parquet format
Also for the purpose of this post, I will use the TPC-DS available in the sample data of Snowflake accounts. You can easily unload that table from Snowflake to Amazon S3 as Parquet files with SQL below.
copy into @mysales.public.aws_external_stage/ — changed the location to parq_files. from ( select * from sample_data.tpcds_sf10tcl.catalog_returns ) file_format = (type = parquet) OVERWRITE=TRUE;
Step 3: Create an external Table
Using the SQL command below, create an External Table pointing to Parquet files stored in an external stage, enabling auto-refresh. More documentation for external table options can be found here.
create or replace external table ext_table_parquet ( CR_RETURNED_DATE_SK string(6) as (value:”_COL_0″::string), CR_RETURNED_TIME_SK NUMBER(38, 0) as (value:”_COL_1″::number), CR_ITEM_SK NUMBER(38, 0) as (value:”_COL_2″::number), CR_REFUNDED_CUSTOMER_SK NUMBER(38, 0) as (value:”_COL_3″::number), CR_REFUNDED_CDEMO_SK NUMBER(38, 0) as (value:”_COL_4″::number), CR_REFUNDED_HDEMO_SK NUMBER(38, 0) as (value:”_COL_5″::number), CR_REFUNDED_ADDR_SK NUMBER(38, 0) as (value:”_COL_6″::number), CR_RETURNING_CUSTOMER_SK NUMBER(38, 0) as (value:”_COL_7″::number), CR_RETURNING_CDEMO_SK NUMBER(38, 0) as (value:”_COL_8″::number), CR_RETURNING_HDEMO_SK NUMBER(38, 0) as (value:”_COL_9″::number), CR_RETURNING_ADDR_SK NUMBER(38, 0) as (value:”_COL_10″::number), CR_CALL_CENTER_SK NUMBER(38, 0) as (value:”_COL_11″::number), CR_CATALOG_PAGE_SK NUMBER(38, 0) as (value:”_COL_12″::number), CR_SHIP_MODE_SK NUMBER(38, 0) as (value:”_COL_13″::number), CR_WAREHOUSE_SK NUMBER(38, 0) as (value:”_COL_14″::number), CR_REASON_SK NUMBER(38, 0) as (value:”_COL_15″::number), CR_ORDER_NUMBER NUMBER(38, 0) as (value:”_COL_16″::number), CR_RETURN_QUANTITY NUMBER(38, 0) as (value:”_COL_17″::number), CR_RETURN_AMOUNT NUMBER(7, 2) as (value:”_COL_18″::number), CR_RETURN_TAX NUMBER(7, 2) as (value:”_COL_19″::number), CR_RETURN_AMT_INC_TAX NUMBER(7, 2) as (value:”_COL_20″::number), CR_FEE NUMBER(7, 2) as (value:”_COL_21″::number), CR_RETURN_SHIP_COST NUMBER(7, 2) as (value:”_COL_22″::number), CR_REFUNDED_CASH NUMBER(7, 2) as (value:”_COL_23″::number), CR_REVERSED_CHARGE NUMBER(7, 2) as (value:”_COL_24″::number), CR_STORE_CREDIT NUMBER(7, 2) as (value:”_COL_25″::number), CR_NET_LOSS NUMBER(7, 2) as (value:”_COL_26″::number)) [email protected]_external_stage file_format = (type = parquet) auto_refresh = true;
Now, let’s get started!
Option 1: COPY command
The COPY command enables loading batches of files available in an external or internal stage. This command uses a customer-managed warehouse to read the files from storage, optionally transform its structure, and write it to native Snowflake tables. COPY also provides file-level transaction granularity as partial data from a file will not be loaded by default ON_ERROR semantics.
COPY into DEST_EXT_TABLE FROM (select $1:_COL_0, $1:_COL_1, $1:_COL_2, $1:_COL_3,$1:_COL_4, $1:_COL_5, $1:_COL_6, $1:_COL_7, $1:_COL_8, $1:_COL_9, $1:_COL_10, $1:_COL_11, $1:_COL_12, $1:_COL_13, $1:_COL_14, $1:_COL_15, $1:_COL_16, $1:_COL_17, $1:_COL_18, $1:_COL_19, $1:_COL_20, $1:_COL_21, $1:_COL_22, $1:_COL_23, $1:_COL_24, $1:_COL_25, $1:_COL_26 from @mysales.public.aws_external_stage/ ) file_format = ( type = PARQUET ) FORCE=TRUE;
If you’re running these SQL commands to calculate your own performance, repeat this job using different warehouse sizes and take note of how long the job took to complete.
Option 2: INSERT as SELECT
With INSERT, we will use the definition of the External Table to add rows to the native Snowflake table.
insert into DEST_EXT_TABLE select CR_RETURNED_DATE_SK , CR_RETURNED_TIME_SK , CR_ITEM_SK , CR_REFUNDED_CUSTOMER_SK , CR_REFUNDED_CDEMO_SK , CR_REFUNDED_HDEMO_SK , CR_REFUNDED_ADDR_SK , CR_RETURNING_CUSTOMER_SK , CR_RETURNING_CDEMO_SK , CR_RETURNING_HDEMO_SK , CR_RETURNING_ADDR_SK , CR_CALL_CENTER_SK , CR_CATALOG_PAGE_SK , CR_SHIP_MODE_SK , CR_WAREHOUSE_SK , CR_REASON_SK , CR_ORDER_NUMBER , CR_RETURN_QUANTITY , CR_RETURN_AMOUNT , CR_RETURN_TAX , CR_RETURN_AMT_INC_TAX , CR_FEE , CR_RETURN_SHIP_COST , CR_REFUNDED_CASH , CR_REVERSED_CHARGE , CR_STORE_CREDIT , CR_NET_LOSS from ext_Table_parquet ;
Once this statement is executed, you will see that the data gets inserted into the Snowflake table at a much higher speed than using the COPY command (more on this later). If you’re following along, repeat this job using different warehouse sizes and take note of the time to execute.
Option 3: Stream on External Table
Now, the third method I’ve used for loading Parquet files on cloud storage to a table is using a stream. More information about streams can be found here, but streams are a great solution for change data capture (CDC) on a table. It is a first-class Snowflake object that records data manipulation language (DML) changes made to tables including inserts, updates, and deleted records as well as metadata about each change. Here, we will use a stream in a slightly different manner to perform batch ingestion.

Step 1: Create a stream on external table
Using the external table created earlier, create a stream. You will see that as records are inserted to the external table, the stream is “hydrated” with the information pertaining to records inserted.
create or replace stream ext_table_stream on external table ext_table_parquet insert_only = true;
Step 2: Create the final table in Snowflake
create or replace TABLE DEST_EXT_TABLE ( CR_RETURNED_DATE_SK NUMBER(38,0), CR_RETURNED_TIME_SK NUMBER(38,0), CR_ITEM_SK NUMBER(38,0), CR_REFUNDED_CUSTOMER_SK NUMBER(38,0), CR_REFUNDED_CDEMO_SK NUMBER(38,0), CR_REFUNDED_HDEMO_SK NUMBER(38,0), CR_REFUNDED_ADDR_SK NUMBER(38,0), CR_RETURNING_CUSTOMER_SK NUMBER(38,0), CR_RETURNING_CDEMO_SK NUMBER(38,0), CR_RETURNING_HDEMO_SK NUMBER(38,0), CR_RETURNING_ADDR_SK NUMBER(38,0), CR_CALL_CENTER_SK NUMBER(38,0), CR_CATALOG_PAGE_SK NUMBER(38,0), CR_SHIP_MODE_SK NUMBER(38,0), CR_WAREHOUSE_SK NUMBER(38,0), CR_REASON_SK NUMBER(38,0), CR_ORDER_NUMBER NUMBER(38,0), CR_RETURN_QUANTITY NUMBER(38,0), CR_RETURN_AMOUNT NUMBER(7,2), CR_RETURN_TAX NUMBER(7,2), CR_RETURN_AMT_INC_TAX NUMBER(7,2), CR_FEE NUMBER(7,2), CR_RETURN_SHIP_COST NUMBER(7,2), CR_REFUNDED_CASH NUMBER(7,2), CR_REVERSED_CHARGE NUMBER(7,2), CR_STORE_CREDIT NUMBER(7,2), CR_NET_LOSS NUMBER(7,2) );
Now we have all three necessary objects created:
- An external table that points to the bucket where Parquet files are stored
- A corresponding stream object
- A destination Snowflake native table
Step 3: Load some data in the S3 buckets
The setup process is now complete. To load the data inside the Snowflake table using the stream, we first need to write new Parquet files to the stage to be picked up by the stream.
copy into @mysales.public.aws_external_stage/ — changed the location to parq_files. from ( select * from Sample_data.tpcds_sf10tcl.catalog_returns ) file_format = (type = parquet) OVERWRITE=TRUE;
This creates megabyte-sized file chunks that will be used for loading the data. Once the data is loaded, it is time to hydrate the stream.
Step 4: Hydrate the Stream
To hydrate the stream, refresh the external table metadata. Because the files are added to the external stage as new, the stream will capture all of the rows from the external table metadata.
alter external table ext_table_parquet refresh;
Step 5: Load data into the table from the stream
As you will see below, we are not using the external table directly to load data, but rather the contents captured in the stream.
insert into dest_ext_table select CR_RETURNED_DATE_SK, CR_RETURNED_TIME_SK, CR_ITEM_SK, CR_REFUNDED_CUSTOMER_SK, CR_REFUNDED_CDEMO_SK, CR_REFUNDED_HDEMO_SK, CR_REFUNDED_ADDR_SK, CR_RETURNING_CUSTOMER_SK, CR_RETURNING_CDEMO_SK, CR_RETURNING_HDEMO_SK, CR_RETURNING_ADDR_SK, CR_CALL_CENTER_SK, CR_CATALOG_PAGE_SK, CR_SHIP_MODE_SK, CR_WAREHOUSE_SK, CR_REASON_SK, CR_ORDER_NUMBER, CR_RETURN_QUANTITY, CR_RETURN_AMOUNT, CR_RETURN_TAX, CR_RETURN_AMT_INC_TAX, CR_FEE, CR_RETURN_SHIP_COST, CR_REFUNDED_CASH, CR_REVERSED_CHARGE, CR_STORE_CREDIT, CR_NET_LOSS from ext_table_stream;
Once you have done this using a specific compute option, repeat steps three through five with different compute sizes that you can configure for Snowflake. You will get a number of readings for the different compute sizes starting from XS all the way to 2XL and beyond.
Comparing results
Below is a comparison of performance for the three load methods using the various warehouse size options.
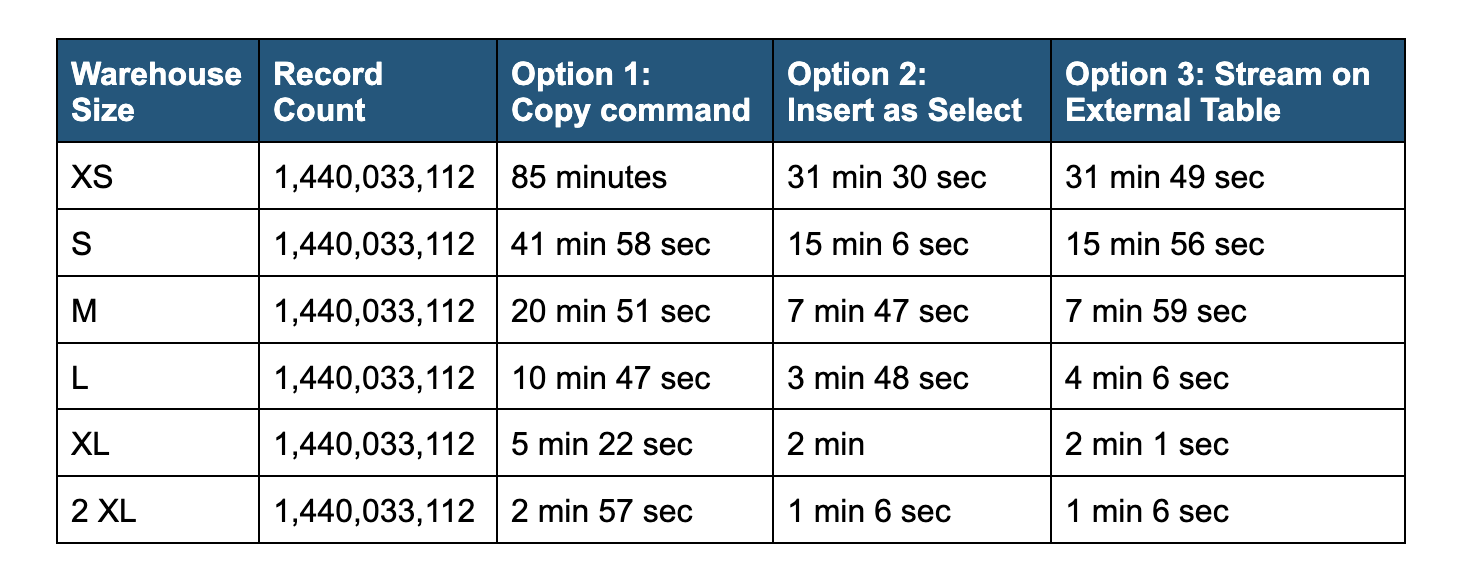

In the chart above, you can see a stark difference in the job duration between Option 1 as compared to Options 2 and 3. Regardless of warehouse size, Options 2 and 3 are roughly twice as fast as Option 1. Why is that so? Snowflake has built a vectorized scanner for querying Parquet files using external tables. Options 2 and 3 benefit from the performance of the vectorized scanner, while COPY command (Option 1) does not. In the future, we may enable vectorized scanner with COPY command as well.
Points to consider
So which option is best for you? Well, that depends! Here are a few points that you should keep in mind when making that decision:
- Options 2 and 3 will only work on external table scans with Parquet files.
- The error handling on data loading via external tables (Options 2 and 3) is minimal compared to COPY command (Option 1).
- I cannot predict the future, but given the rate at which new features are introduced at Snowflake, I don’t expect it will be long before there is closer parity in performance between these 3 different ways of batch loading Parquet files into a Snowflake table.
If you’re looking for a more generalized overview of external tables in Snowflake, I’d recommend our documentation for external tables.
Have questions? Join and get answers from our Snowflake community.
{kind=link}