
 |
With Amazon Redshift, you can analyze data in the cloud at any scale. Amazon Redshift offers native data protection capabilities to protect your data using automatic and manual snapshots. This works great by itself, but when you’re using other AWS services, you have to configure more than one tool to manage your data protection policies.
To make this easier, I am happy to share that we added support for Amazon Redshift in AWS Backup. AWS Backup allows you to define a central backup policy to manage data protection of your applications and can now also protect your Amazon Redshift clusters. In this way, you have a consistent experience when managing data protection across all supported services. If you have a multi-account setup, the centralized policies in AWS Backup let you define your data protection policies across all your accounts within your AWS Organizations. To help you meet your regulatory compliance needs, AWS Backup now includes Amazon Redshift in its auditor-ready reports. You also have the option to use AWS Backup Vault Lock to have immutable backups and prevent malicious or inadvertent changes.
Let’s see how this works in practice.
Using AWS Backup with Amazon Redshift
The first step is to turn on the Redshift resource type for AWS Backup. In the AWS Backup console, I choose Settings in the navigation pane and then, in the Service opt-in section, Configure resources. There, I toggle the Redshift resource type on and choose Confirm.
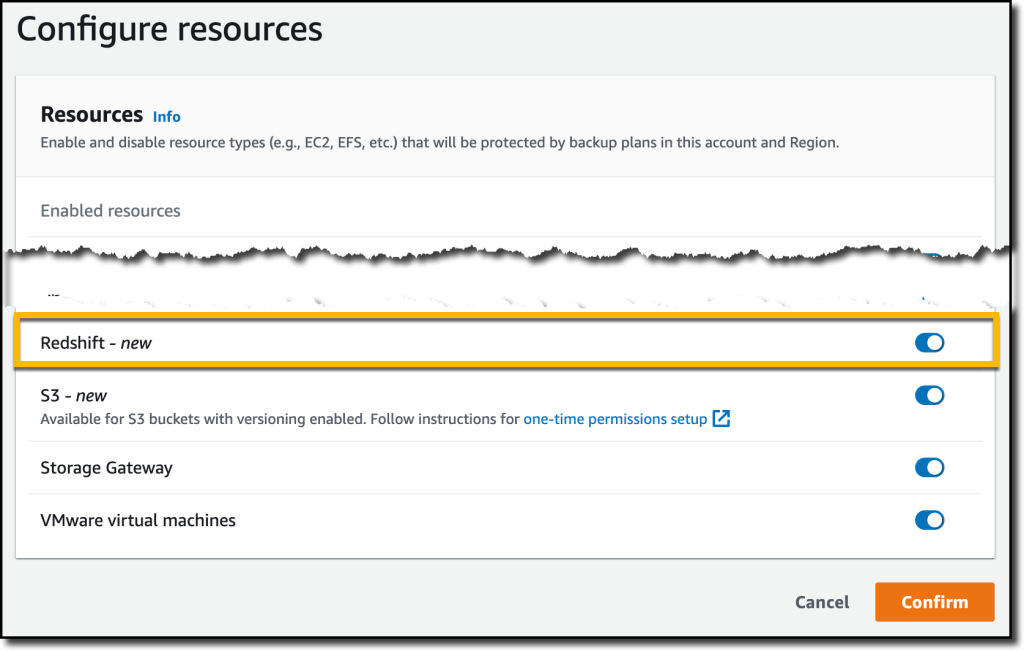
Now, I can create or update a backup plan to include the backup of all, or some, of my Redshift clusters. In the backup plan, I can define how often these backups should be taken and for how long they should be kept. For example, I can have daily backups with one week of retention, weekly backups with one month of retention, and monthly backups with one year of retention.
I can also create on-demand backups. Let’s see this with more details. I choose Protected resources in the navigation pane and then Create on-demand backup.
I select Redshift in the Resource type dropdown. In the Cluster identifier, I select one of my clusters. For this workload, I need two weeks of retention. Then, I choose Create on-demand backup.

My data warehouse is not huge, so after a few minutes, the backup job has completed.
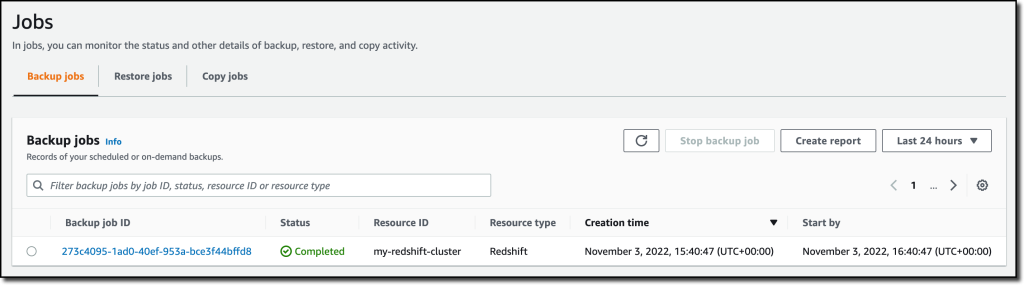
I now see my Redshift cluster in the list of the resources protected by AWS Backup.
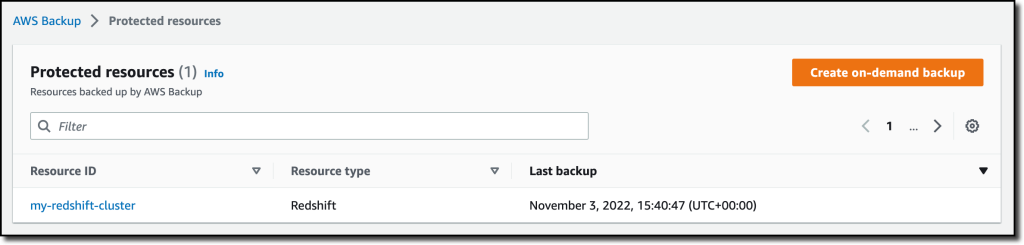
In the Protected resources list, I choose the Redshift cluster to see the list of the available recovery points.

When I choose one of the recovery points, I have the option to restore the full data warehouse or just a table into a new Redshift cluster.

I now have the possibility to edit the cluster and database configuration, including security and networking settings. I just update the cluster identifier, otherwise the restore would fail because it must be unique. Then, I choose Restore backup to start the restore job.
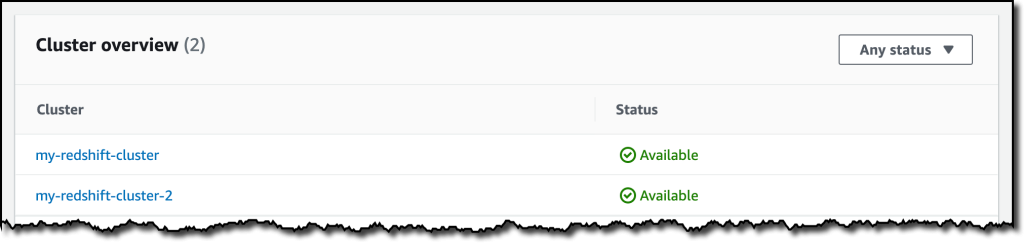
After some time, the restore job has completed, and I see the old and the new clusters in the Amazon Redshift console. Using AWS Backup gives me a simple centralized way to manage data protection for Redshift clusters as well as many other resources in my AWS accounts.
Availability and Pricing
Amazon Redshift support in AWS Backup is available today in the AWS Regions where both AWS Backup and Amazon Redshift are offered, with the exception of the Regions based in China. You can use this capability via the AWS Management Console, AWS Command Line Interface (CLI), and AWS SDKs.
There is no additional cost for using AWS Backup compared to the native snapshot capability of Amazon Redshift. Your overall costs depend on the amount of storage and retention you need. For more information, see AWS Backup pricing.
— Danilo

{kind=link}