
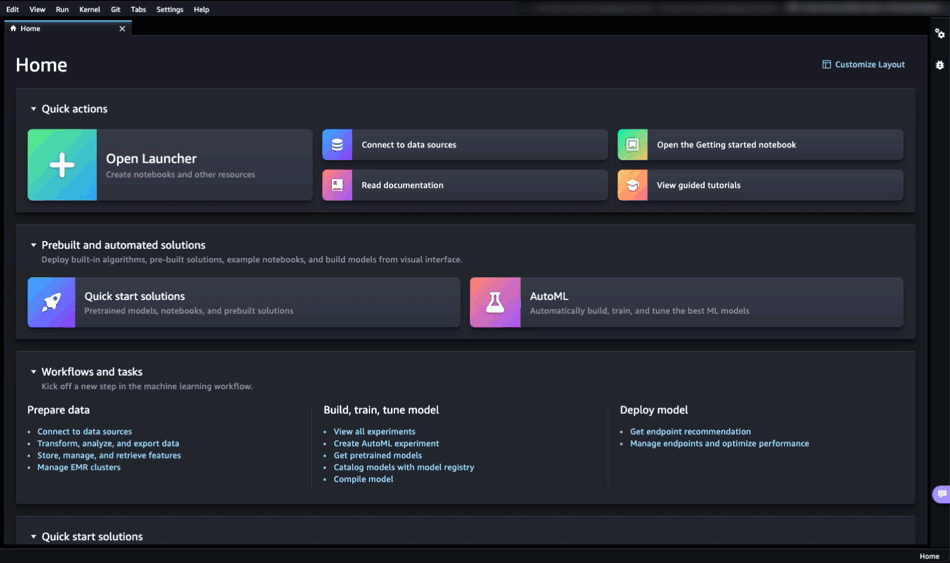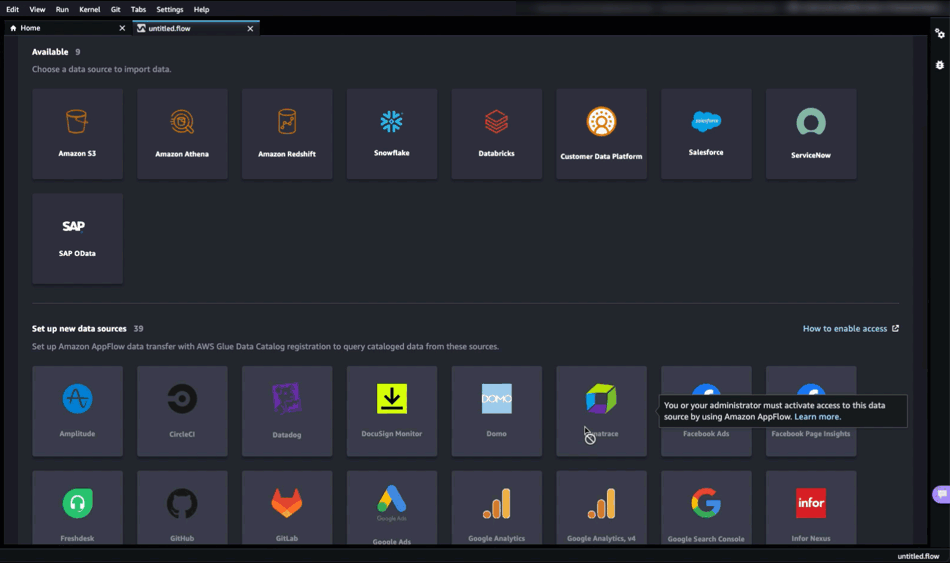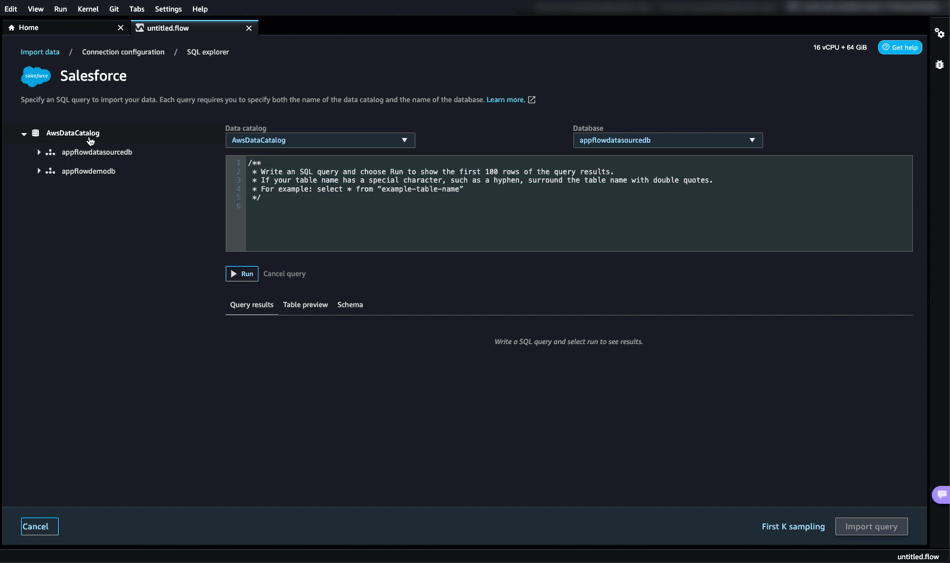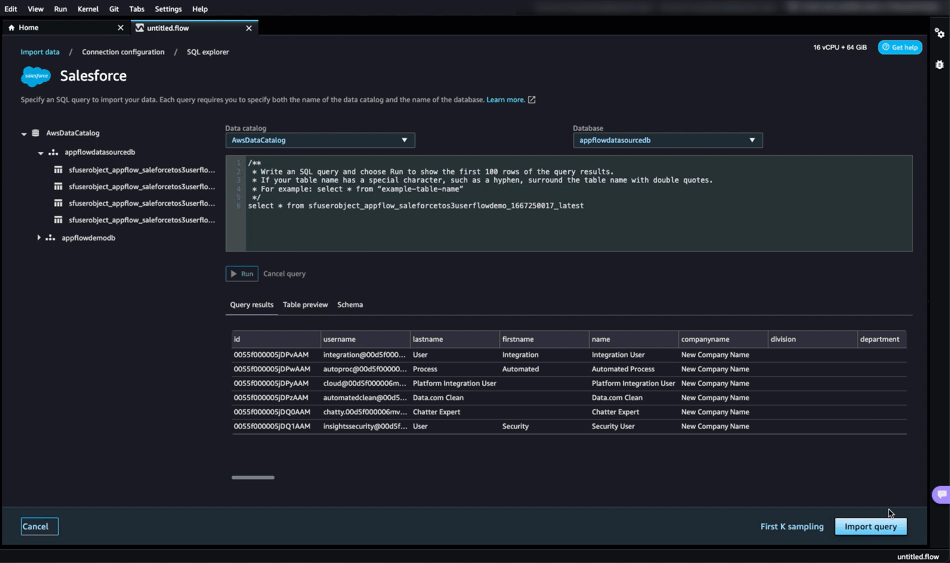
Snowflake continues to set the standard for data in the cloud by removing the need to perform maintenance tasks on your data platform and giving you the freedom to choose your data model methodology for the cloud. One possible integration issue is the need to deal with a batch file that arrives out of sequence. Does that mean you need to roll back the previous day’s batch data to get the data sequence in order? Does it mean that the dashboard reports need to be rolled back and the corrections explained?
This post is number 10 in our “Data Vault Techniques on Snowflake” series (but is being delivered “out of sequence” to you before number 9):
- Immutable Store, Virtual End Dates
2. Snowsight Dashboards for Data Vault
3. Point-in-Time Constructs and Join Trees
4. Querying Really Big Satellite Tables
5. Streams and Tasks on Views
6. Conditional Multi-Table INSERT, and Where to Use It
7. Row Access Policies + Multi-Tenancy
8. Hub Locking on Snowflake
10. Out-of-Sequence Data
9. Virtual Warehouses and Charge Back
A reminder of the data vault table types:

To be thorough, we also want to consider the following variations of satellite tables as they too can be compromised by late-arriving or out-of-sequence batch data:

Surrounding business objects (hub tables) and transactions (link tables), you may have a need for the following satellite table types:

Yes, they could also be affected by out-of-sequence batch data.
All of the above satellites (excluding the effectivity satellite tables, or EFS) can be managed with the addition of the following satellite table:

File-based automation has a file-based extract date. This is essentially the applied date that, according to the source platform, all the states of the business objects that source system is automating are active. Whether this is a snapshot or delta feed is irrelevant—the data presented to the analytics platform is the current state of that business object.
The problem may occur (for numerous reasons) when we receive state data out of sequence, or late arriving. Since a data vault tracks changes, an out-of-sequence load may present some business data integrity issues. But within the data vault we have the extended automation pattern to deal with this, and deal with it dynamically. This pattern is only possible because with Data Vault 2.0 we do not physicalize the end dates (as we saw in blog post 1), we virtualize them. Here’s the problem scenario:
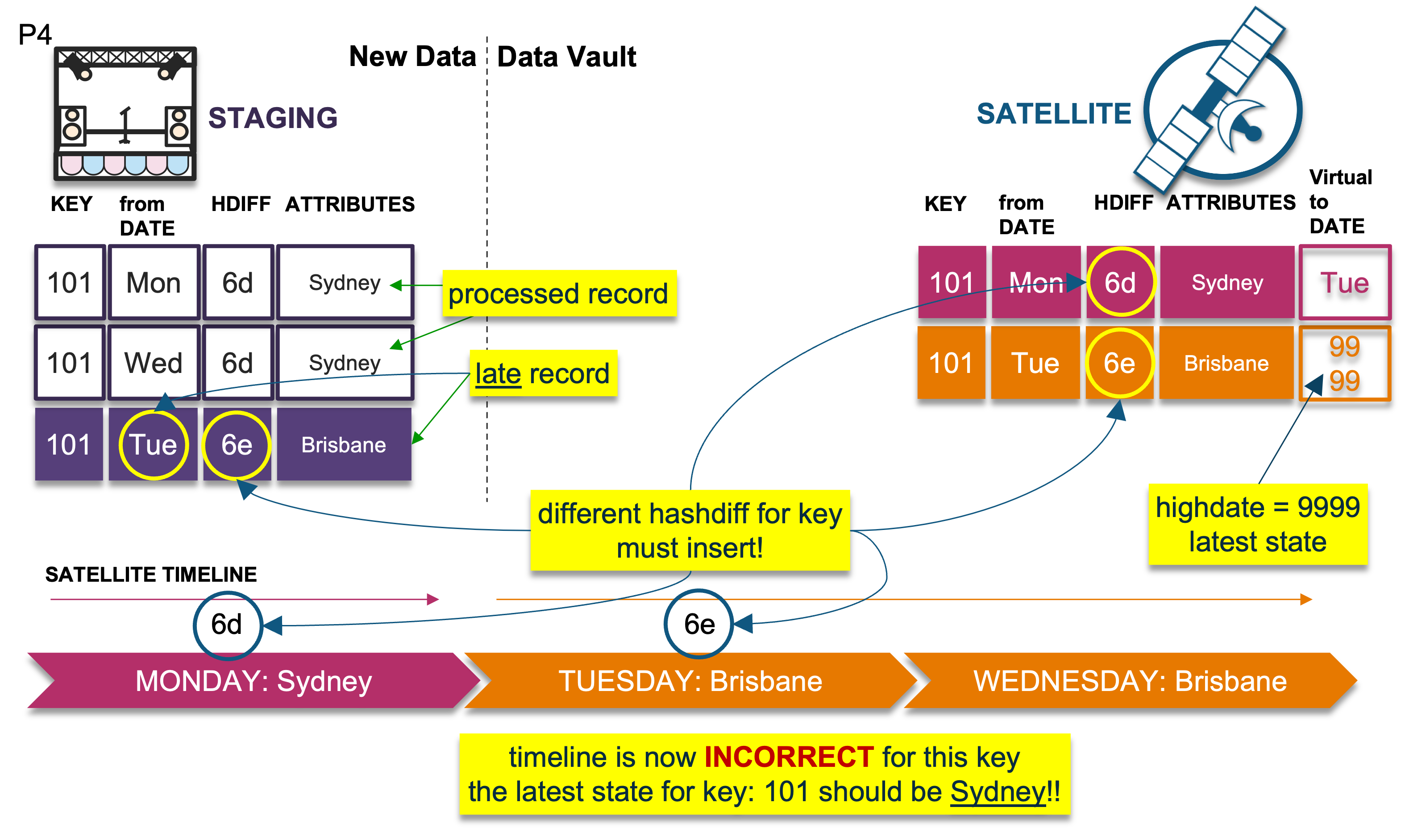 Problem Scenario
Problem Scenario
Let’s use the diagram above to help us visualize the problem and the solution.
On the left of the diagram is the landed data, and for simplicity we will track a single business key. We have already processed the first two records into the target satellite table on the right. We received a Monday record, and then a Wednesday record. Because each record’s hashdiff (the record digest we use to compare new against existing records) was the same (“Sydney” on Monday and “Sydney” again on Wednesday), we end up with only the first occurrence of Sydney in the target satellite table. The late-arriving record is the key’s state for Tuesday—its hashdiff differs from the older record of Monday (“Sydney”). Therefore, we must insert that record, and because we have inserted that record the active state of the key is now incorrect.
To recap, our timeline now shows “Brisbane” as the active record when it should be “Sydney” instead:
- Monday: Sydney
- Wednesday: Sydney, no need to insert into the satellite table because it is the same as Monday
- Tuesday: Brisbane, a late-arriving record; we must insert but now the timeline is incorrect
Data Vault does have an automation pattern to deal with batch or file-based data that arrives out of sequence. With a little ingenuity we can extend the record tracking satellite artifact to track records for all satellites around a hub or link table.
Extending the record tracking satellite
A single extended record tracking satellite (XTS) will be used to manage out-of-sequence data for each hub and link table. Data Vault’s record tracking satellite (RTS) records hashdiffs for the applied date. We will change that to track the record digest, and extend RTS to include the target satellite table name within XTS itself, denoting which adjacent satellite that hashdiff belongs to.

Column descriptions
- Hash Key is the hash key belonging to a satellite table.
- Load Date is the date the record was loaded.
- Applied Date is the package of time date.
- Record Target is the name of the satellite table that the hashdiff belongs to.
- HashDiff comes from the landed data but represents the applicable record-hash digest of the adjacent satellite table. We record it in XTS for every occurrence of that record coming in from the landed content.
XTS will be thin, and we will record every hashdiff that comes in from the landed data for that satellite table, even if it has not changed. The adjacent satellite table will, of course, contain the descriptive attributes, whereas XTS table will not.
Now let’s look at how XTS can help load Data Vault satellite tables through five different scenarios.
Five common scenarios for your XTS
Scenario 1: Every delta is the same
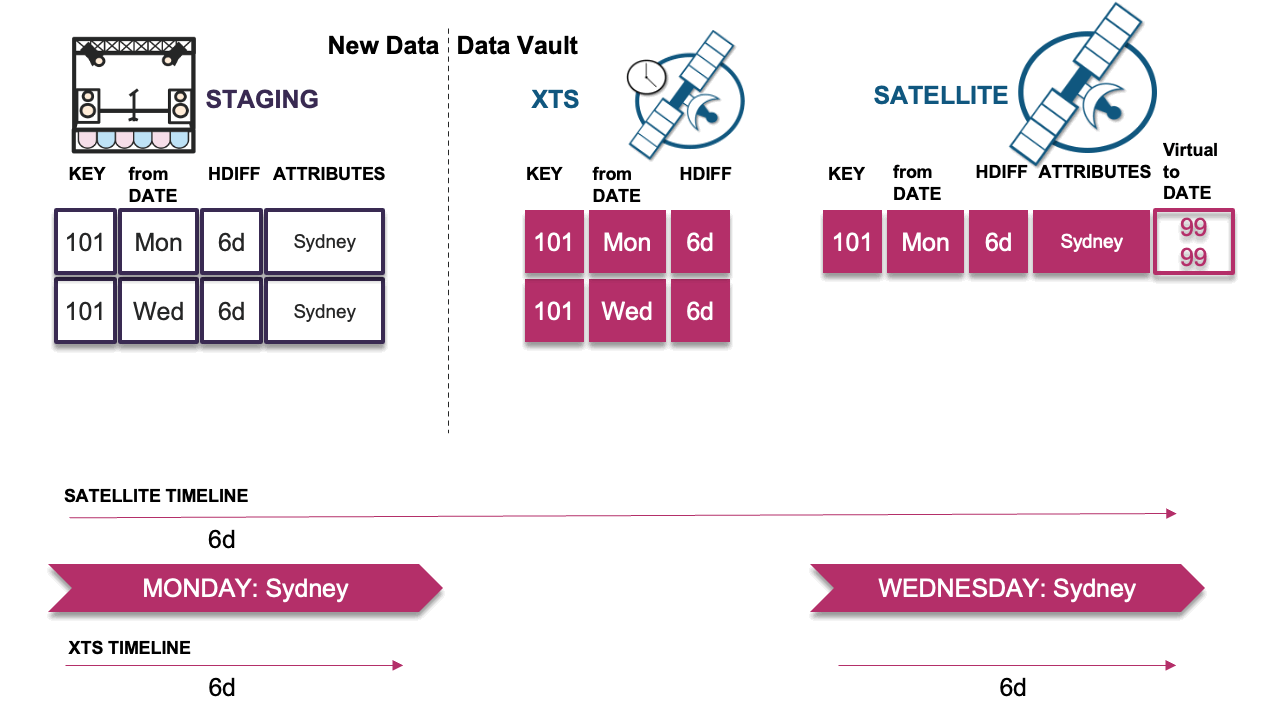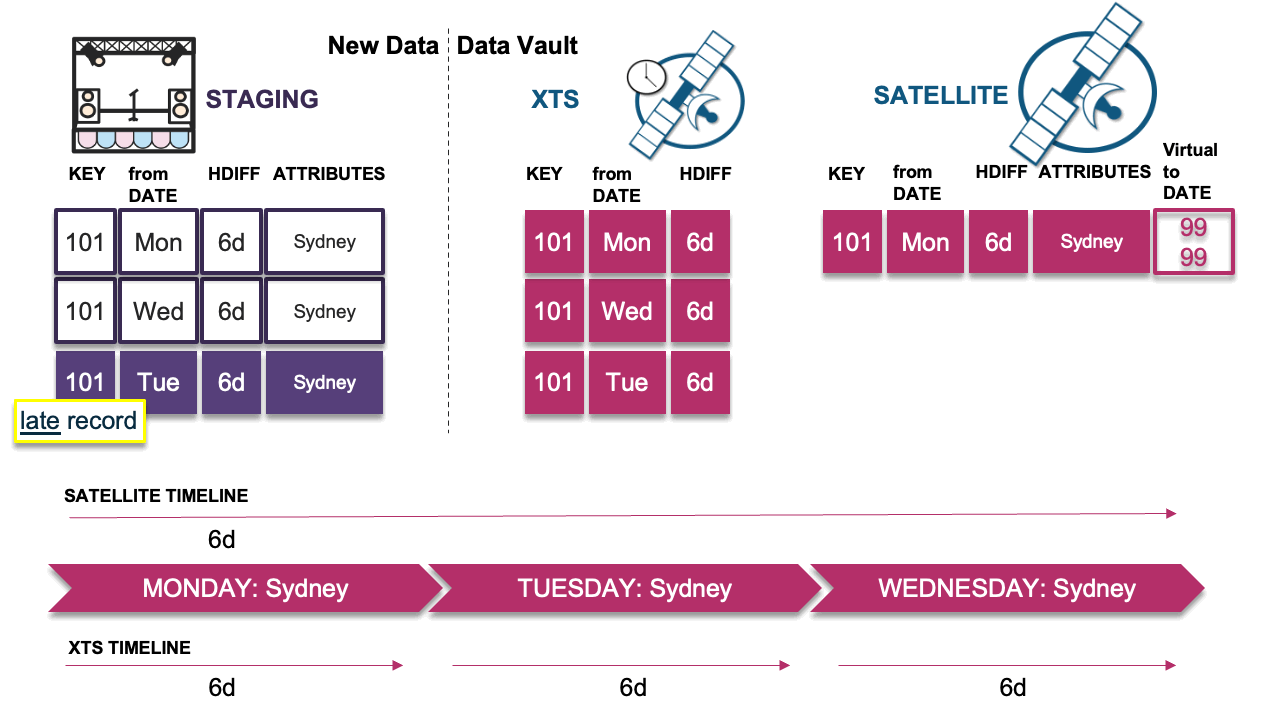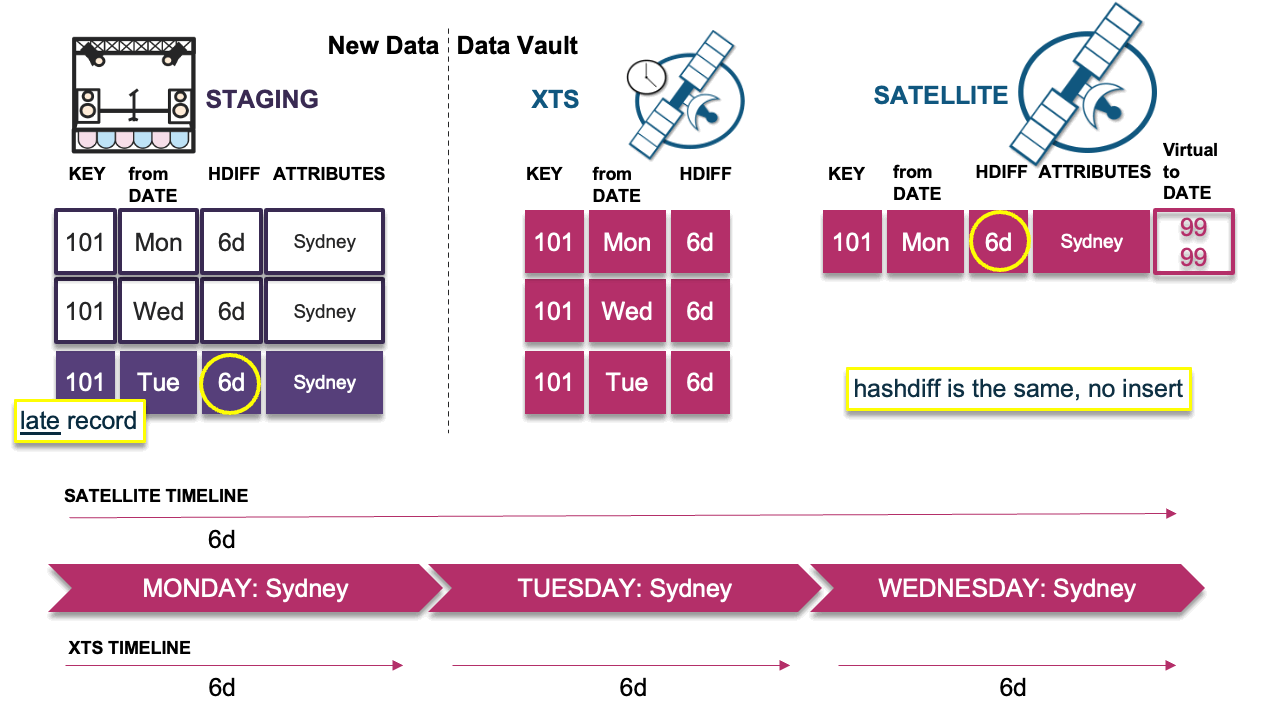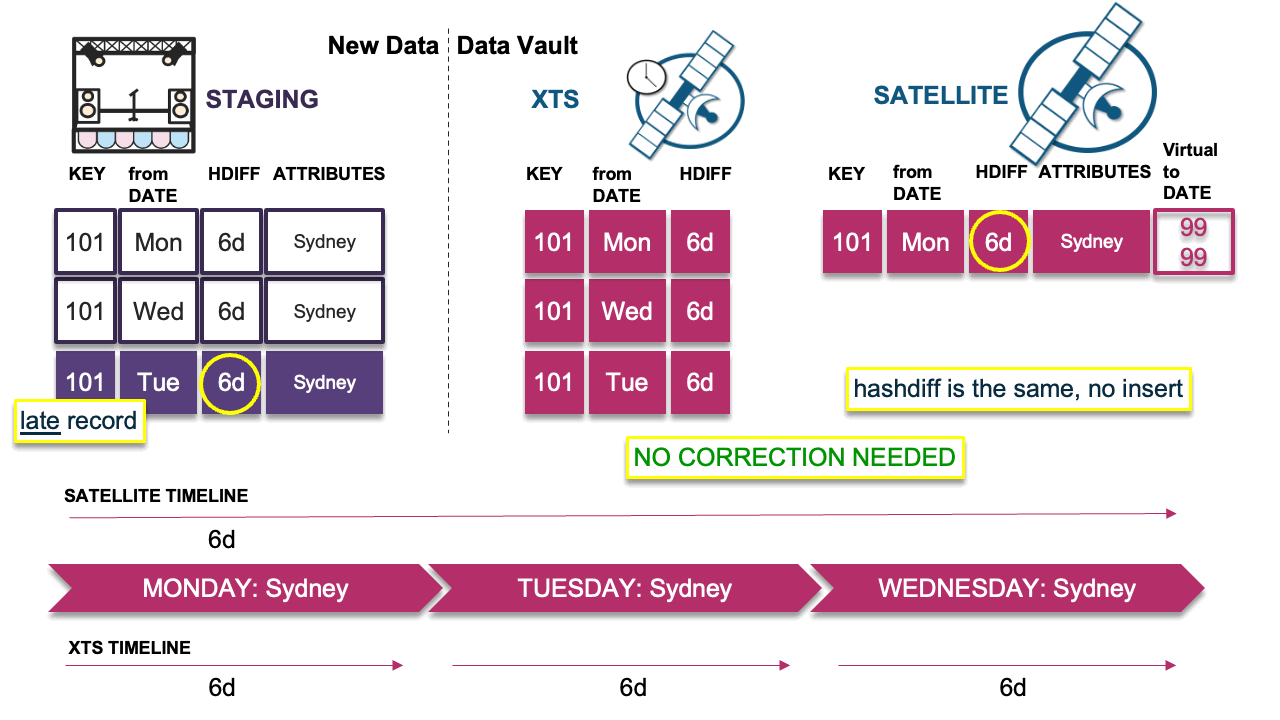
Let’s start with an easy example.The late record arrived, and its hashdiff is the same as the previous and next records in the timeline. We record the hashdiff in XTS and load nothing into the satellite table because the hashdiff has not changed.
Scenario 2: Every delta is different
In this scenario, the late-arriving delta record differs from the previous record; therefore, we must insert the record. The new record does not compromise the timeline and we record the hashdiff in the XTS table and insert the record into the adjacent satellite table.
Scenario 3: Late record is the same as previous
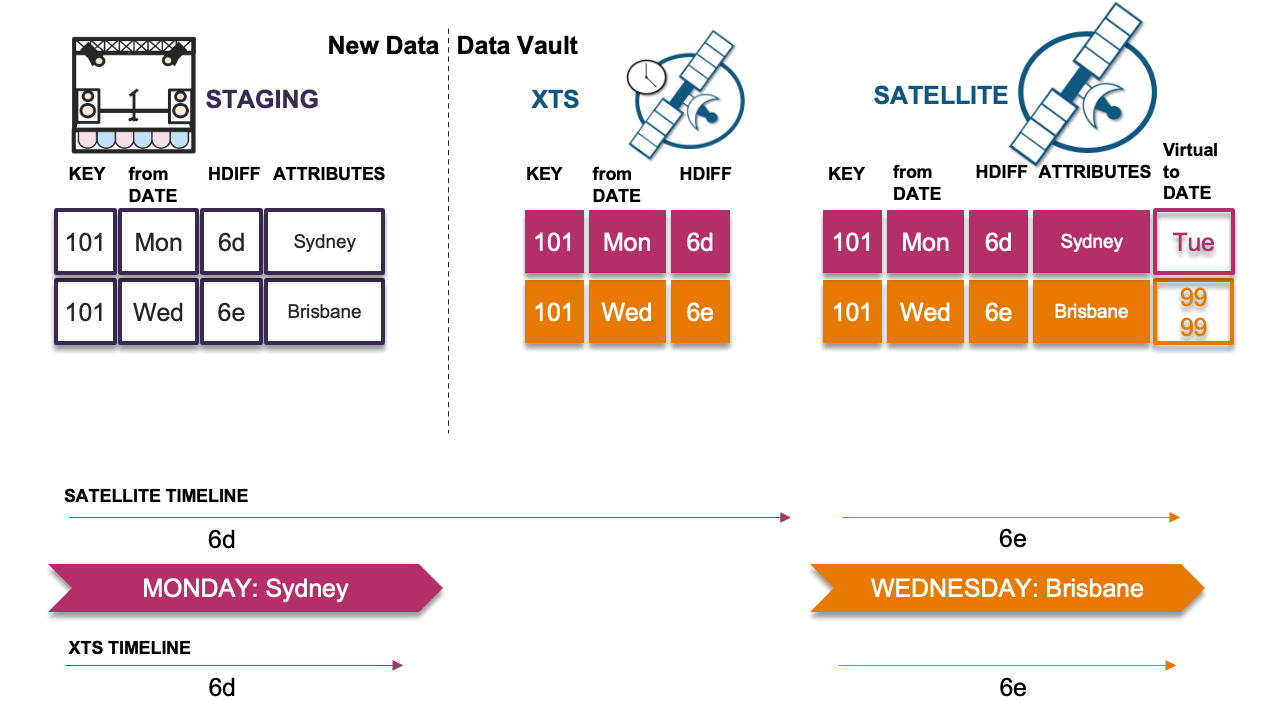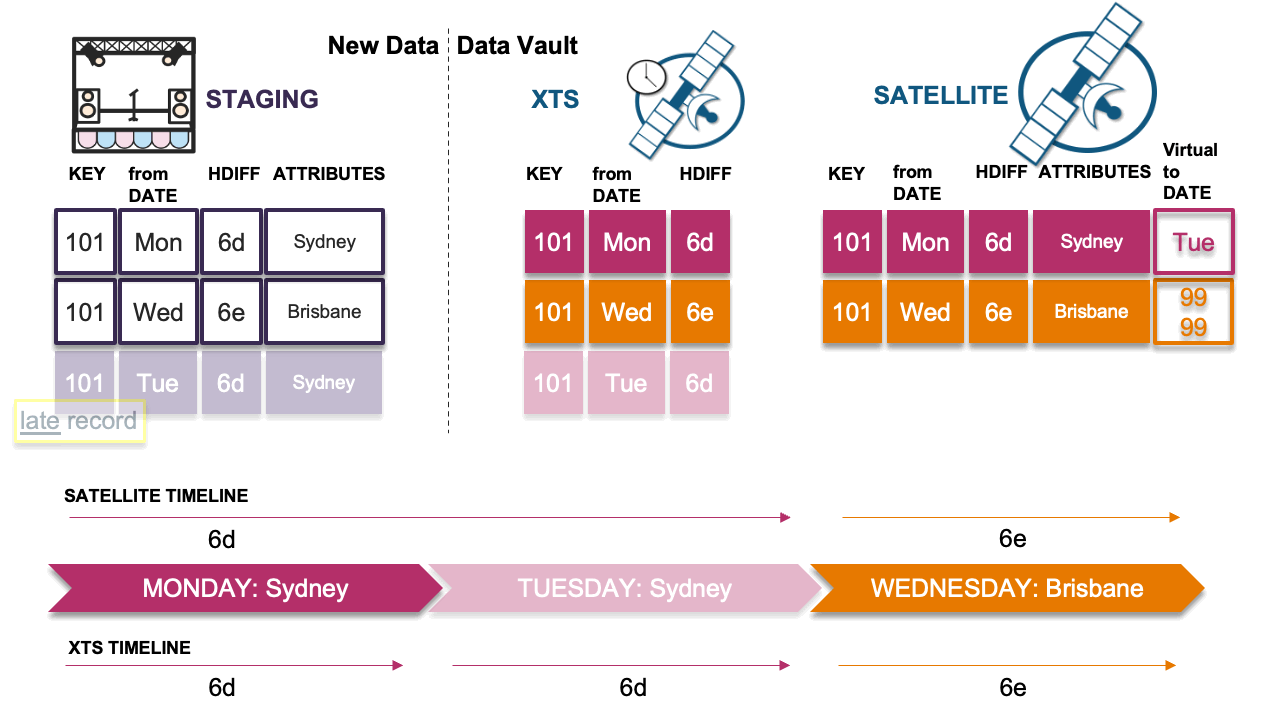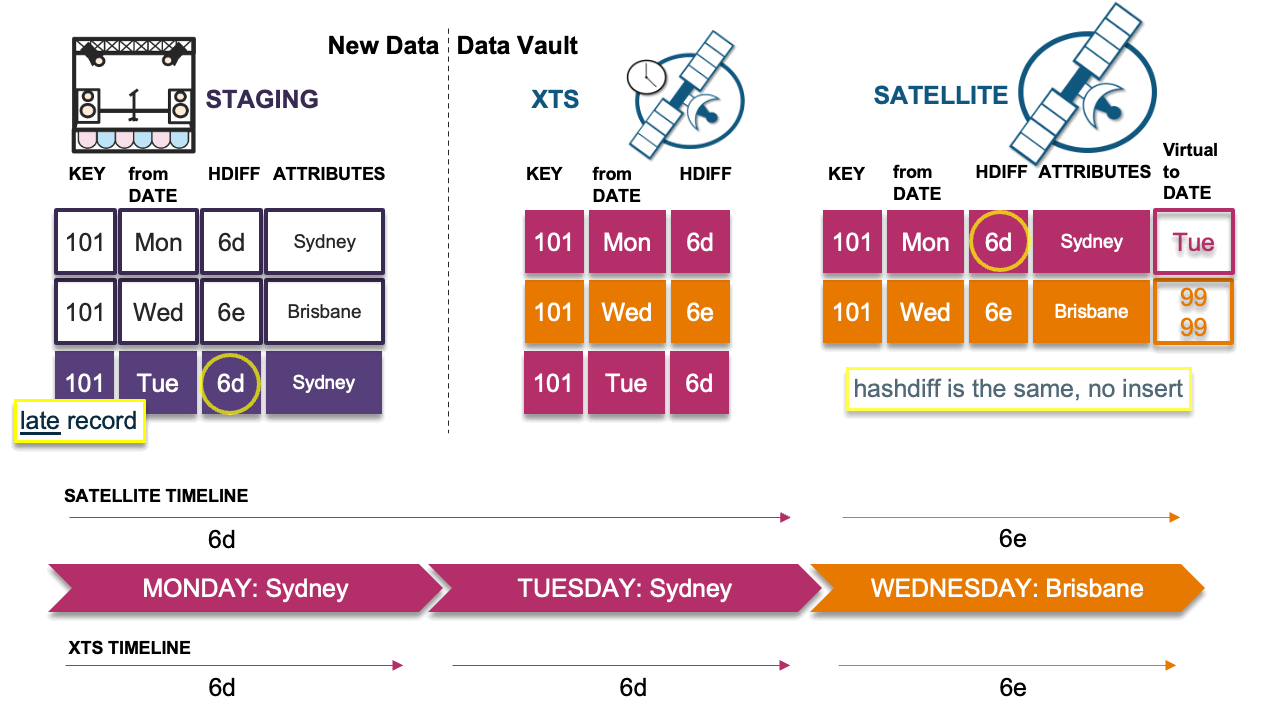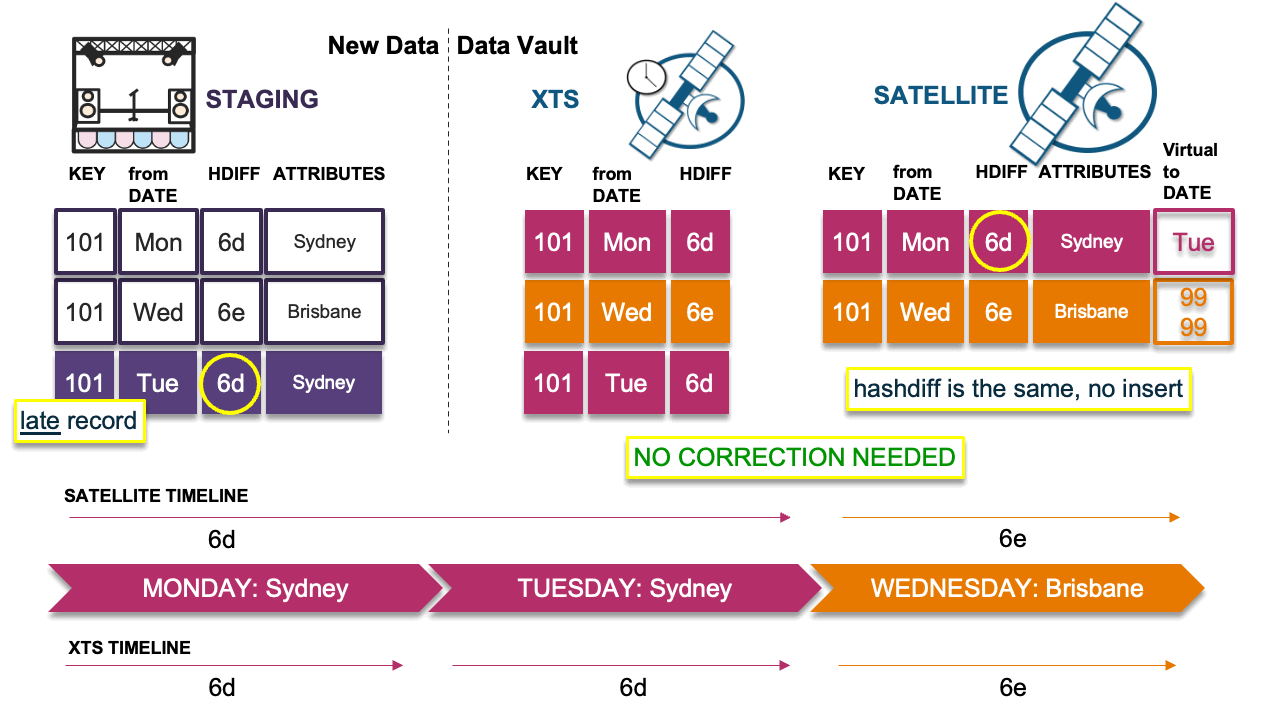
Here the late-arriving record has the same hashdiff as the previous record in the timeline. No insert is needed in the satellite table and the timeline remains the same. The record hashdiff is inserted into the XTS table.
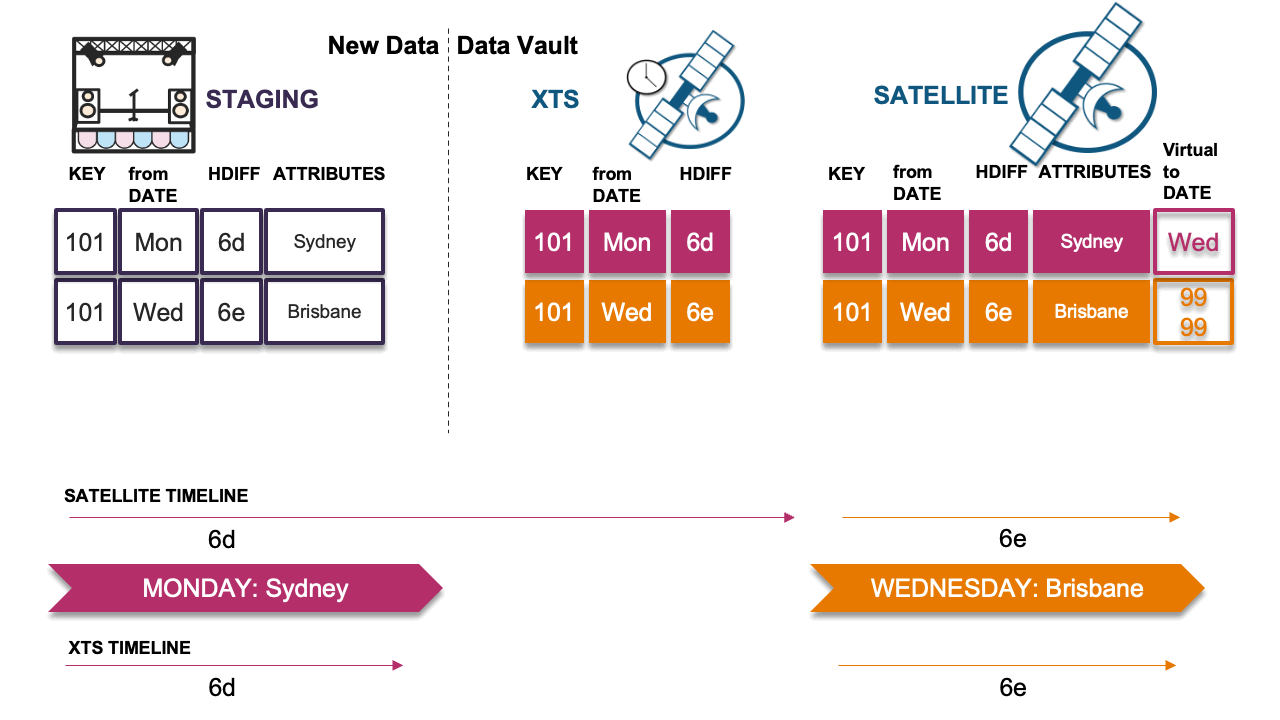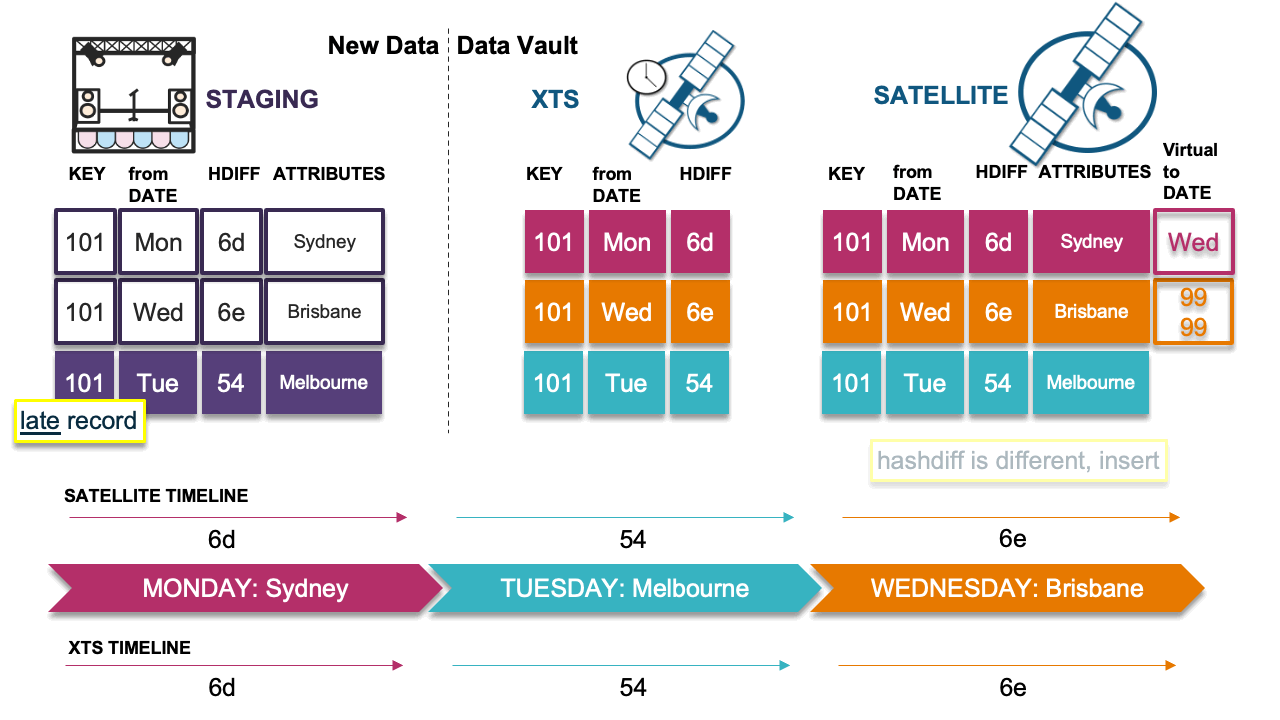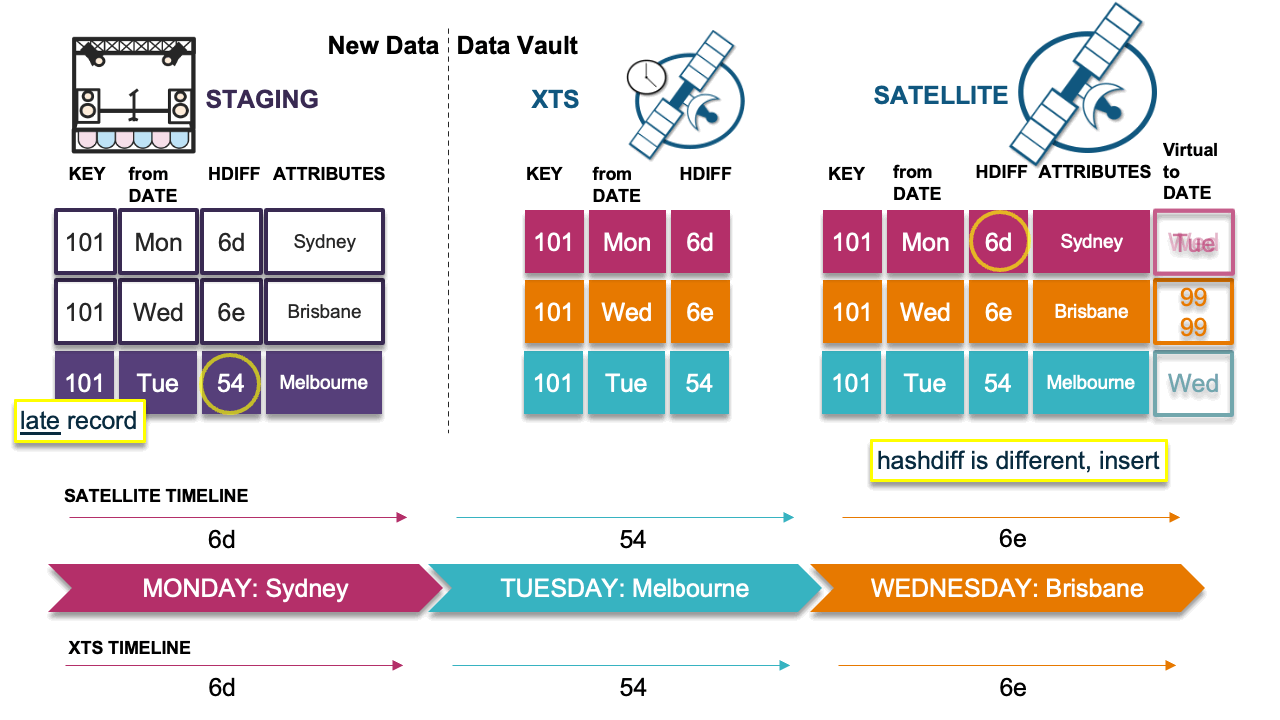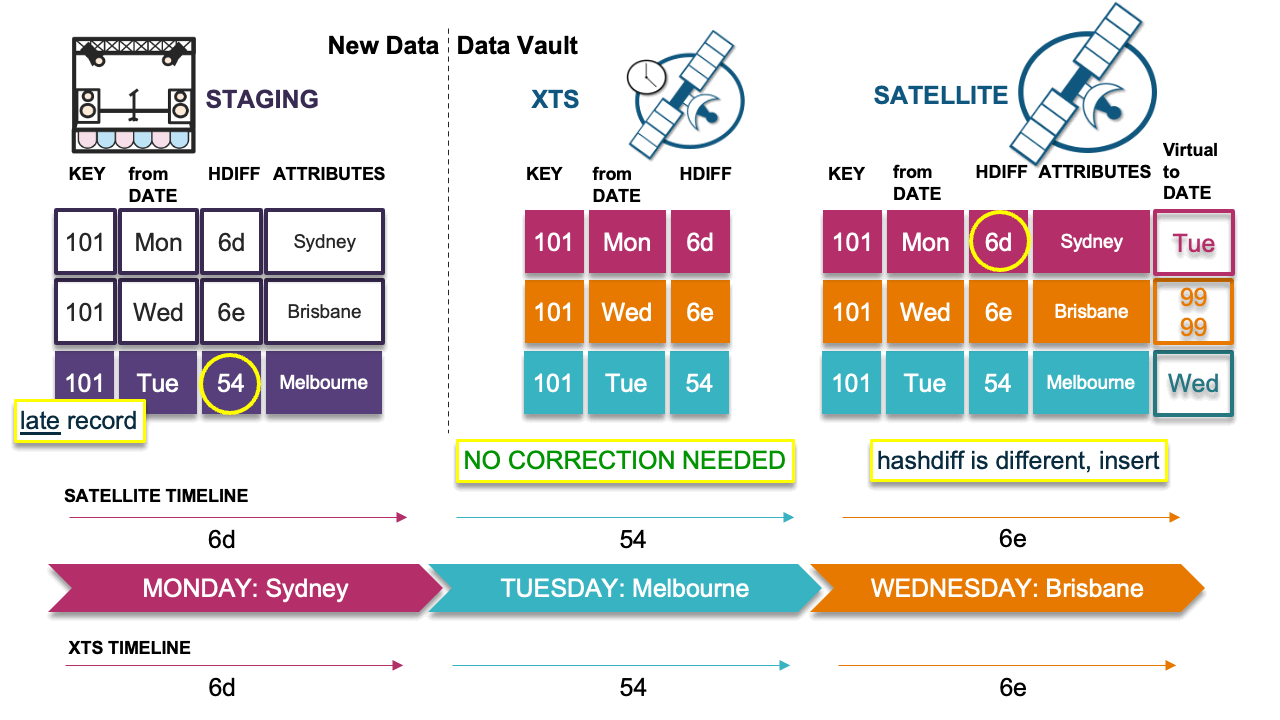
Scenario 4: Late record causes timeline issue
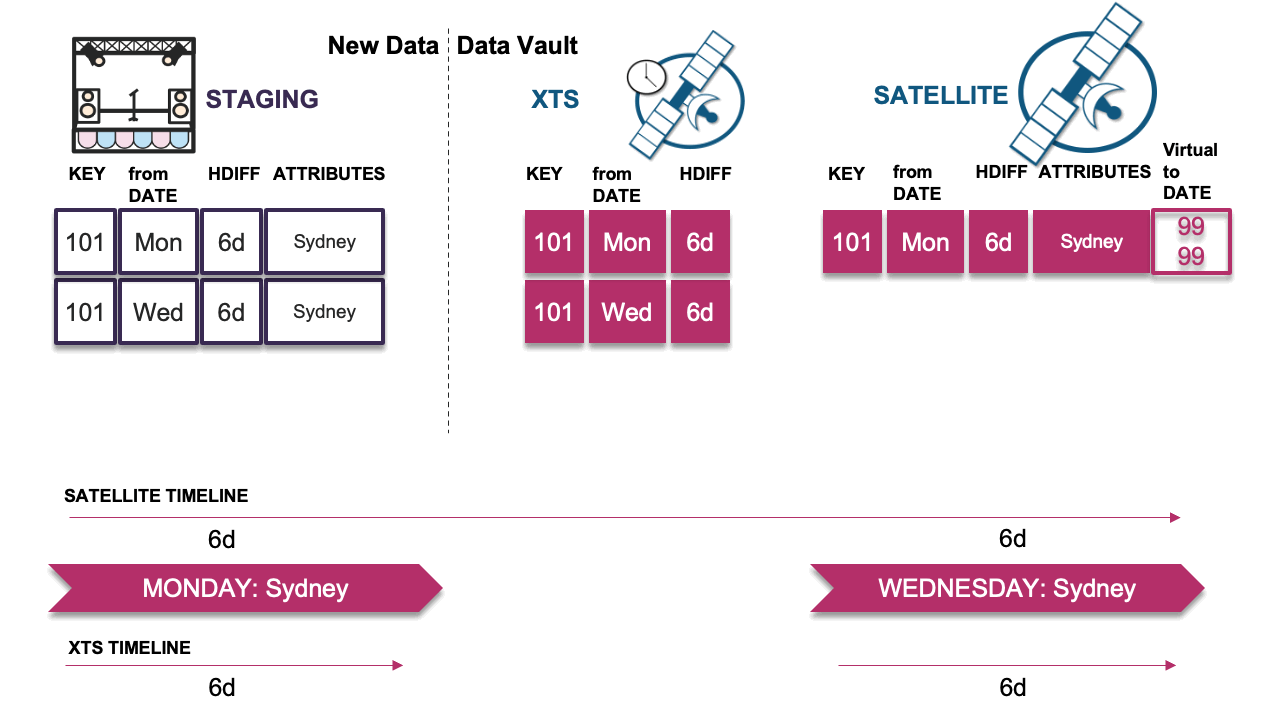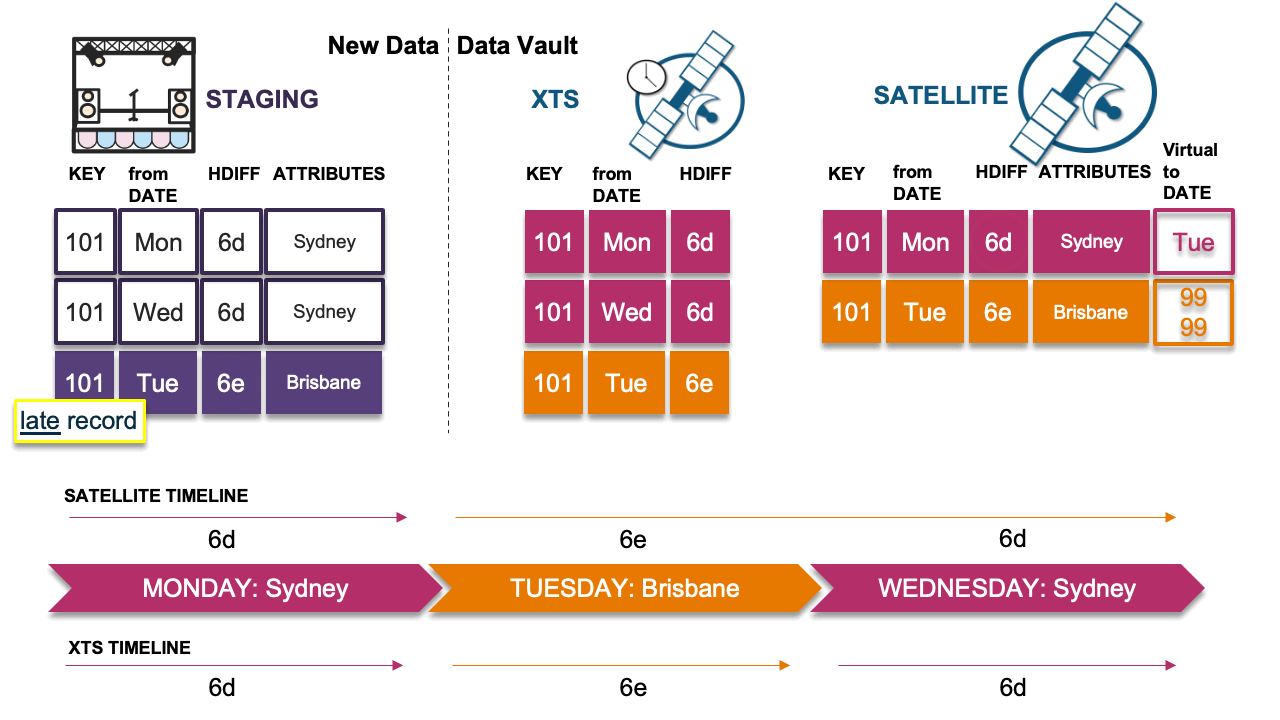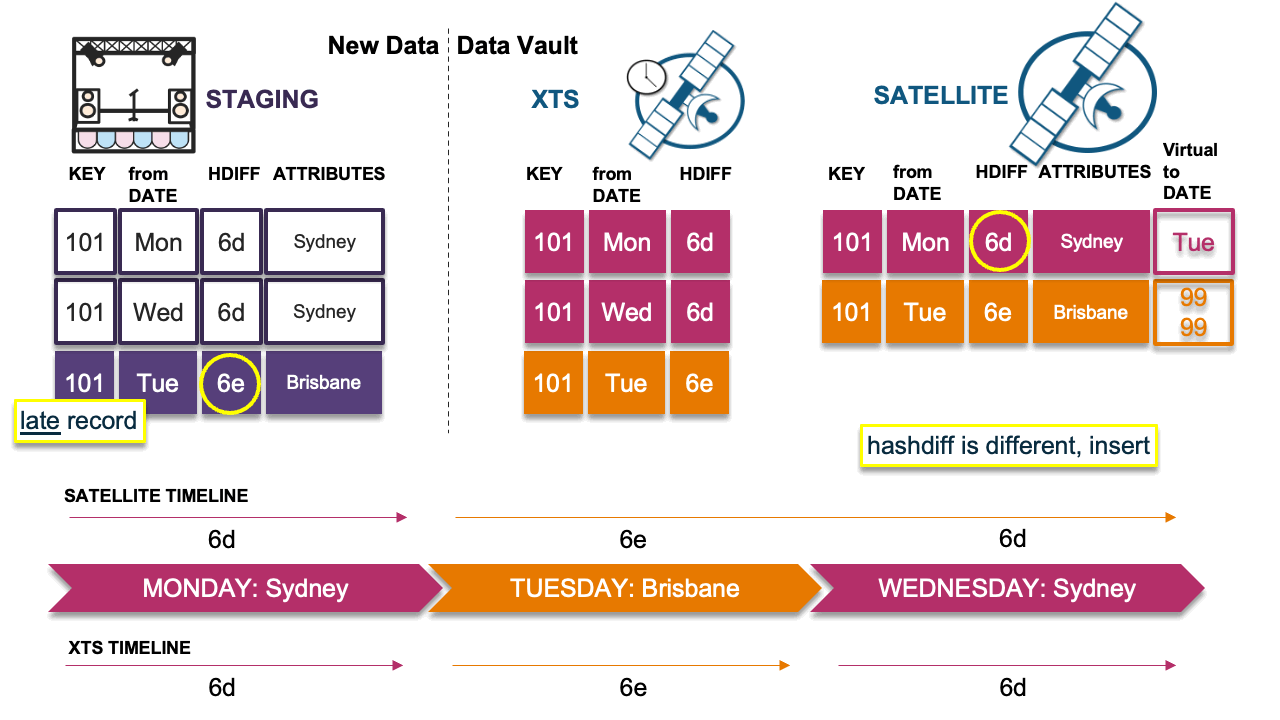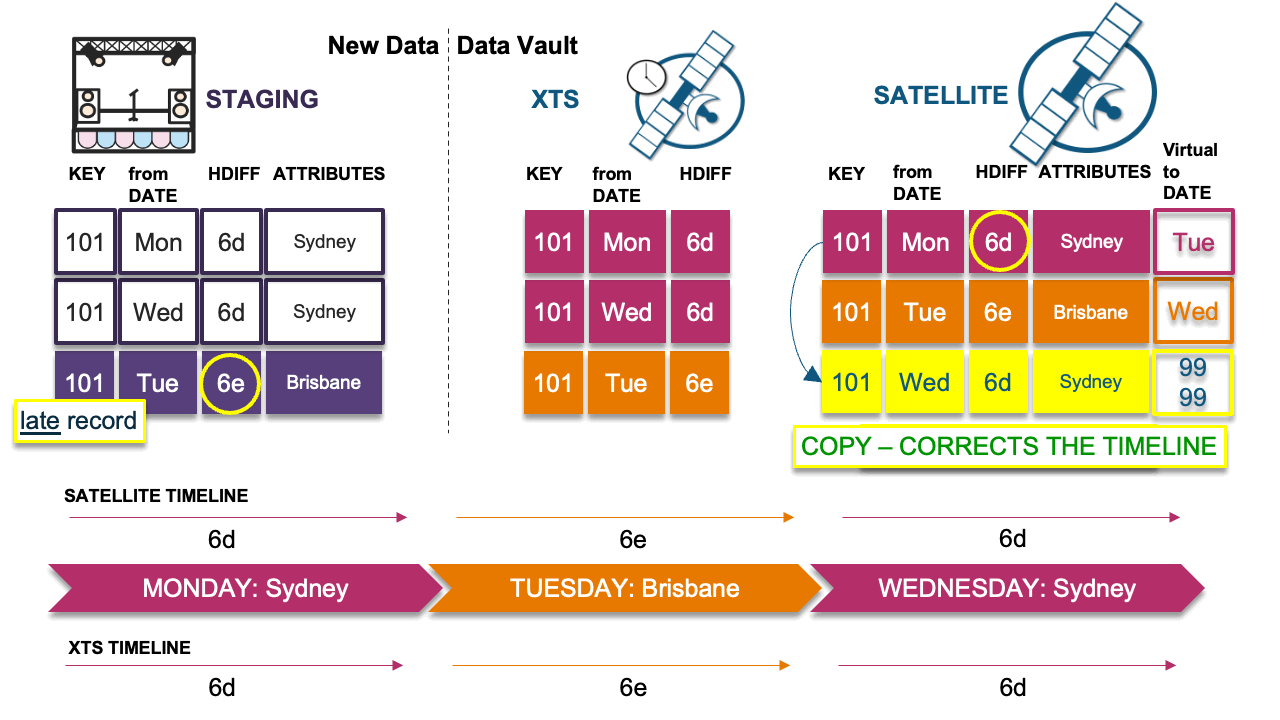
In this scenario, the late record’s hashdiff differs from the previous record’s hashdiff in the timeline; we must insert this delta. However, because we have done so, the timeline now appears incorrect. This is the problem scenario described earlier. We must now copy the previous record (Monday) in the satellite table and insert it as Wednesday’s record into the satellite table with the descriptive details from Monday, which will then correct the timeline.
Note that the virtual end-dates are naturally correct based on the physical table underneath. If the end dates were physicalized, we would have to resort to running SQL UPDATEs on the table and churning more Snowflake micro-partitions than needed. Because we have stuck to the INSERT-ONLY paradigm, this pattern can deal with any velocity of table loads elegantly.
And finally…
Scenario 5: Delta happened earlier
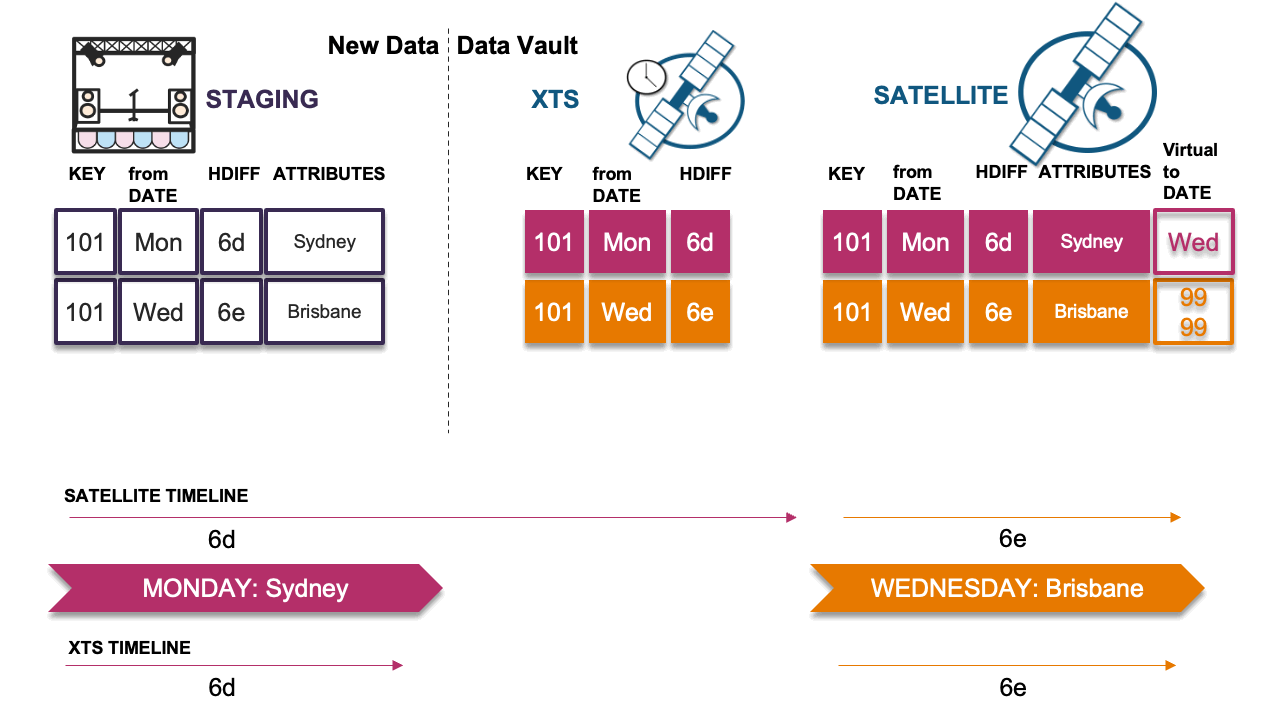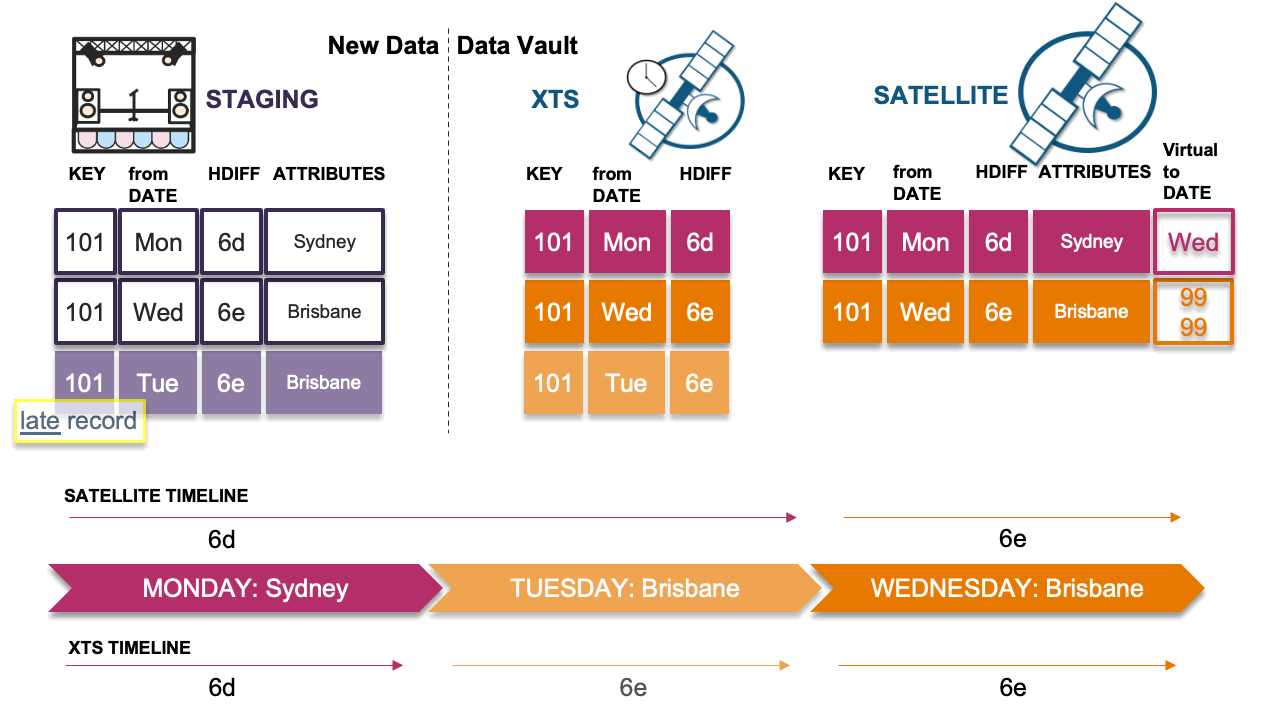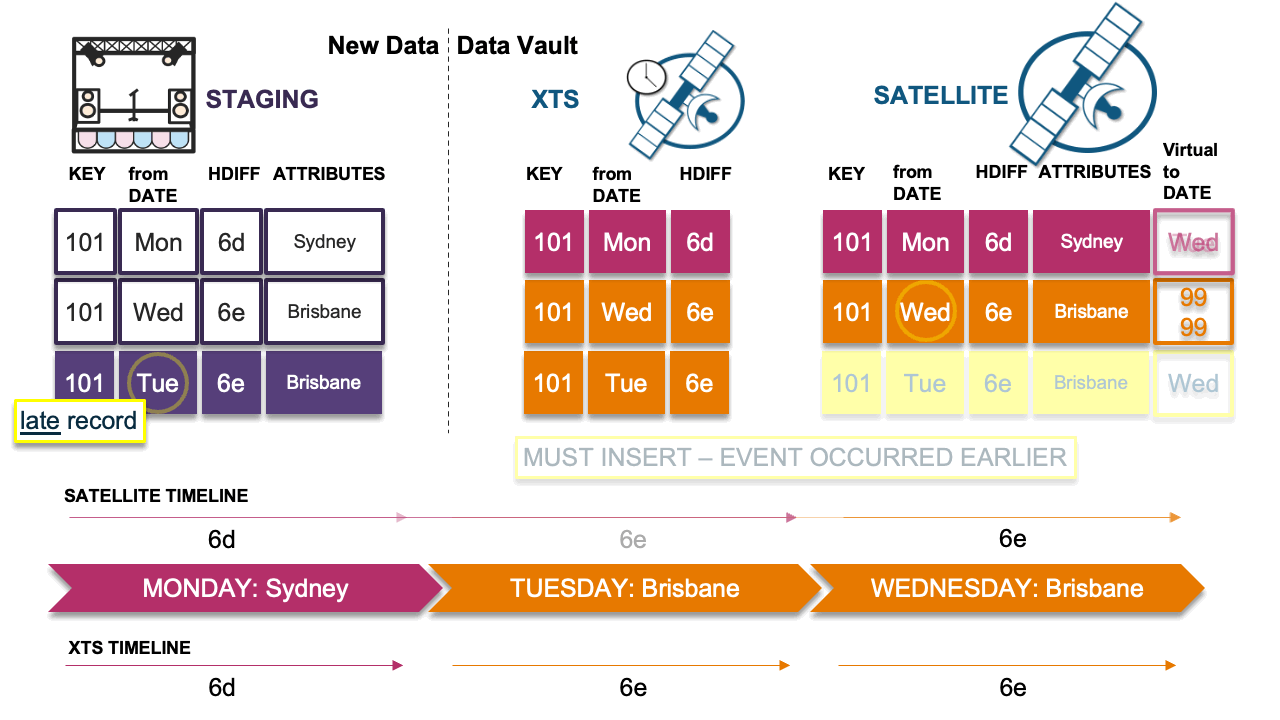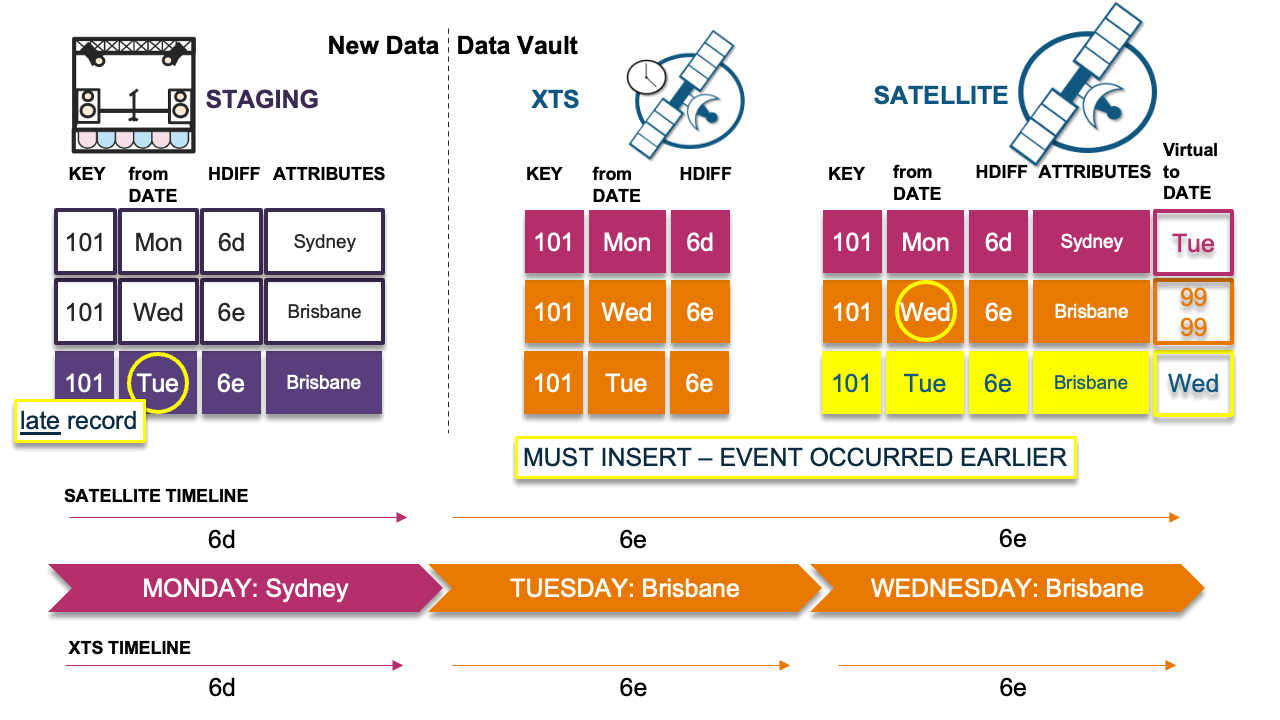
In this final scenario the late-arriving record must be inserted because Wednesday’s event or state occurred earlier (it happened on Tuesday). You will end up with a duplicate record in the satellite table but now the timeline is correct. Is the integrity of the satellite table now broken? You could argue no, because you are using the point-in-time (PIT) and bridge tables (outlined in blog post 3, Data Vault Techniques on Snowflake: Point-in-Time (PIT) Constructs and Join Trees) to fetch the single record applicable at a snapshot date, and those query assistance tables will pick one record or the other based on that snapshot date.
For this and the earlier scenarios, it does mean that when you have a correction event (scenario 4), you will likely need to rebuild your PIT and bridge tables, and the views based on those query assistance tables do not need any update at all. Remember, in Data Vault query assistance tables and information marts are disposable. That’s what sets them apart from the auditable raw and business vaults.
Orchestration
Alas, orchestration is vital for making this pattern a success.
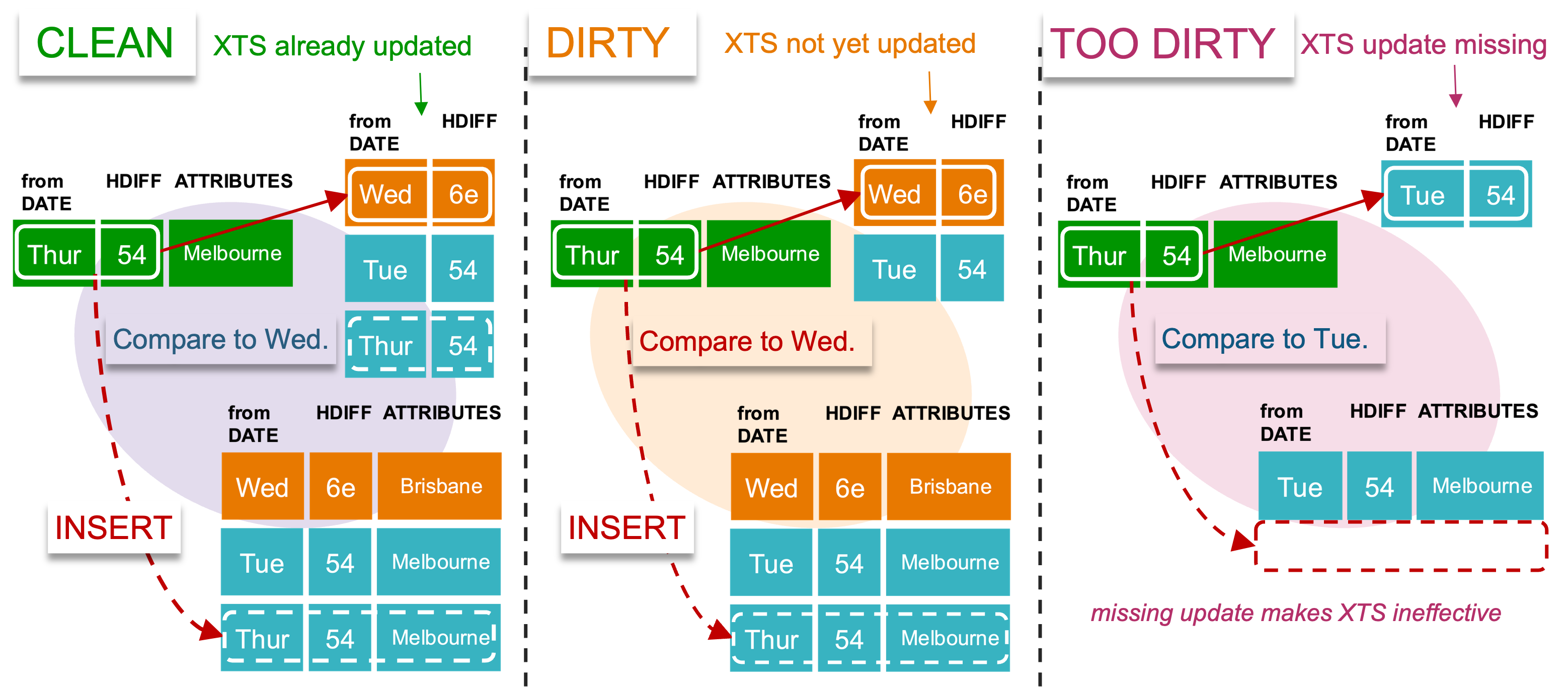 Don’t let the updates get too dirty!
Don’t let the updates get too dirty!
An adjacent satellite table can be updated before or after XTS has been updated with the same delta within a batch run. Correcting the timeline is about the record before and after the delta, and not about the current delta.
Thanks to Snowflake READ COMMITTED transaction isolation level, you do not need to lock the central XTS table for updating or reading—we discussed this point for hub table locking in blog post 8, Hub Locking on Snowflake. Remember, a raw vault satellite table is single source, so you won’t have contention in XTS for a raw vault satellite table, and therefore you could have as many threads as you like using and updating a common XTS table concurrently and without contention.
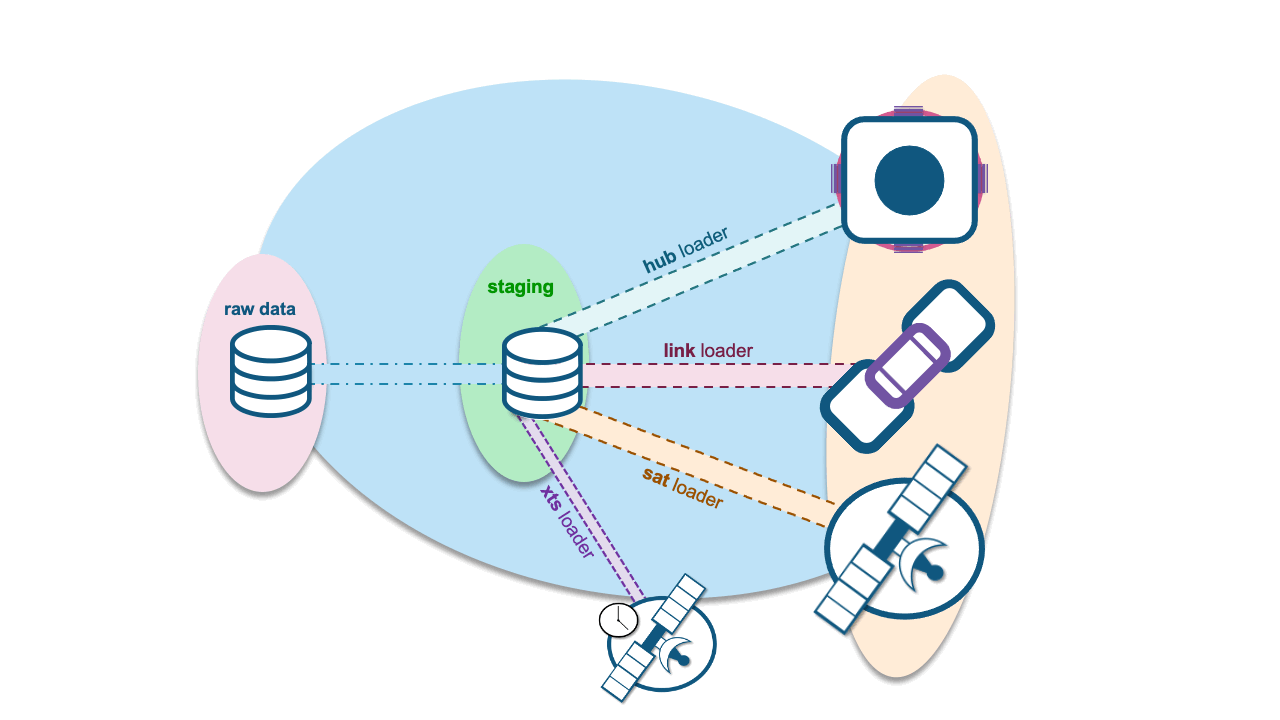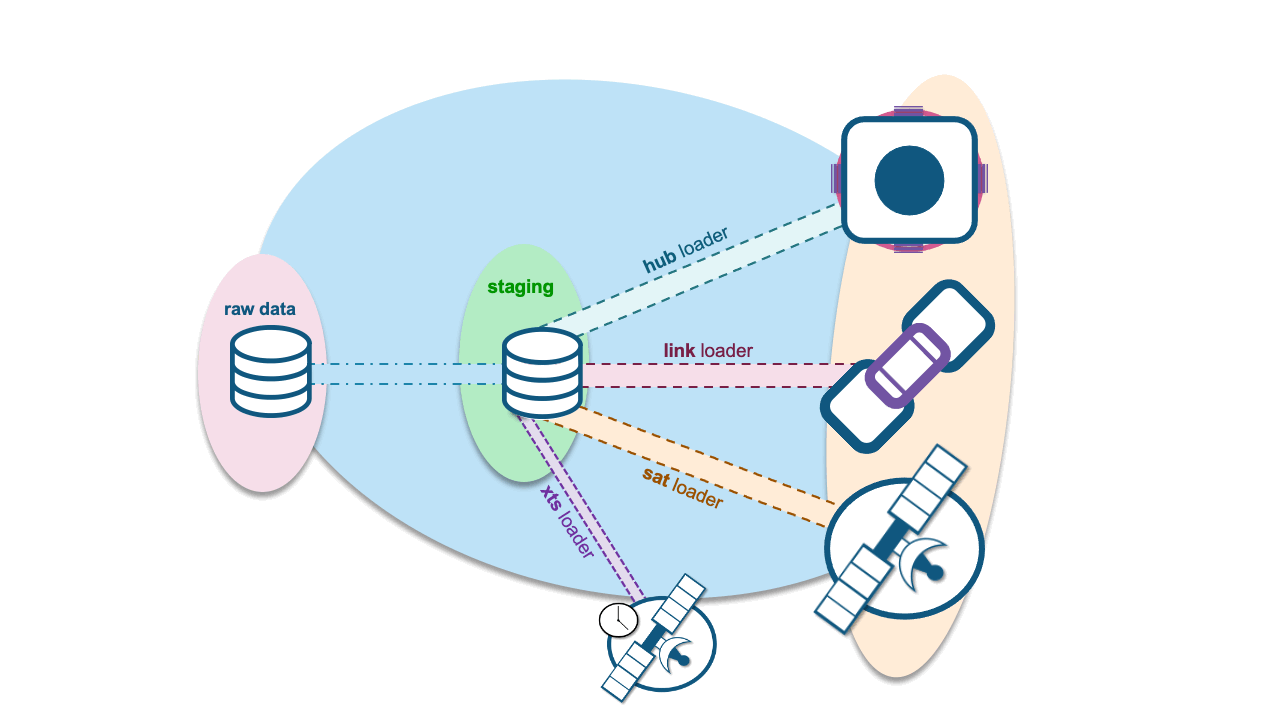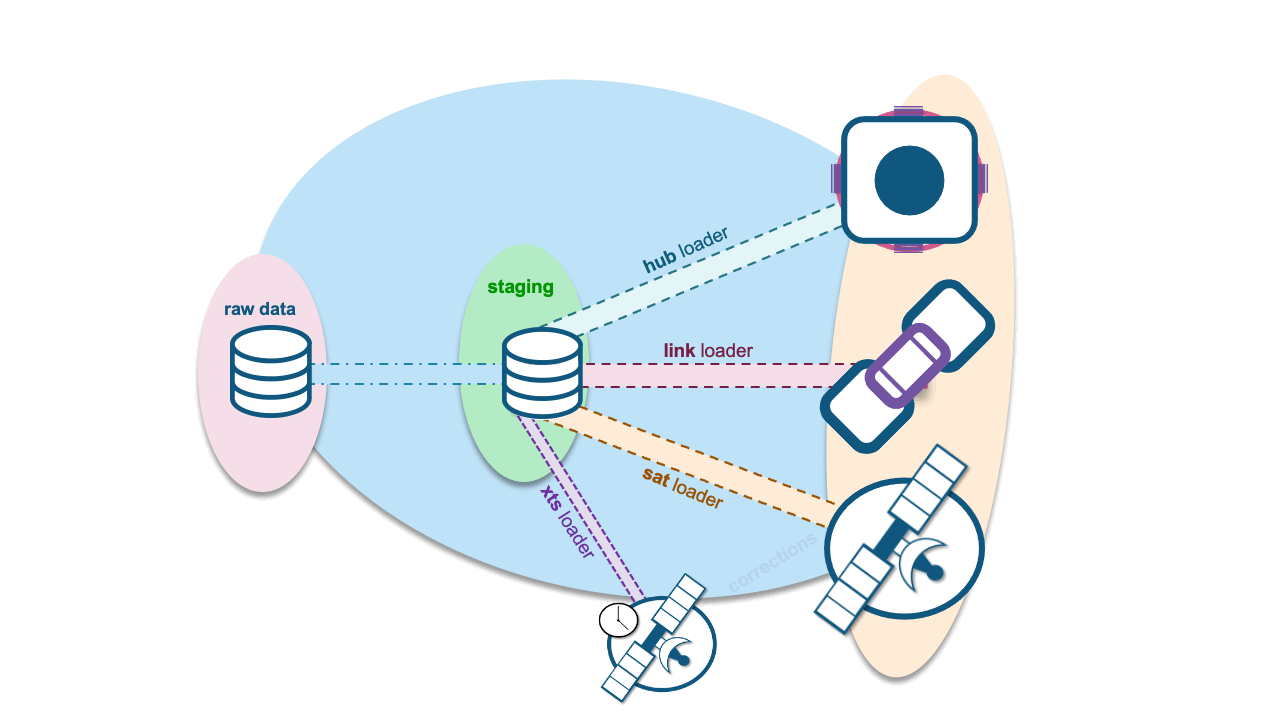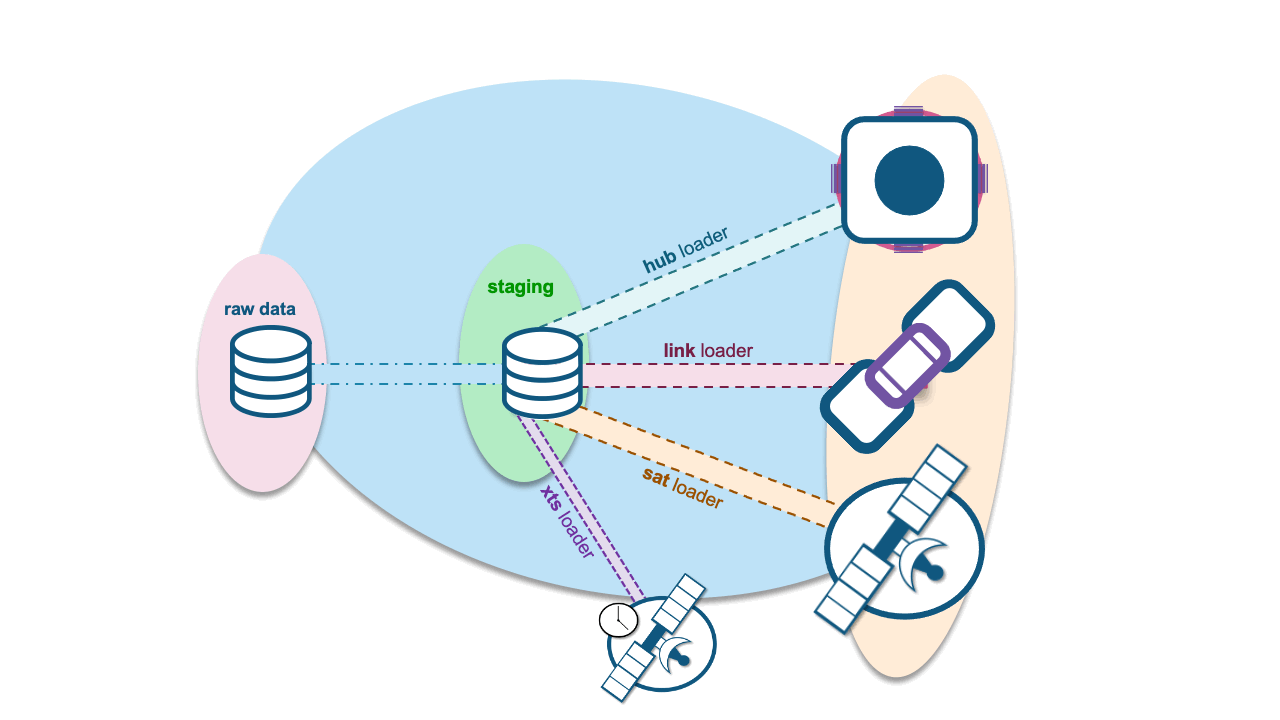 XTS influences satellite table loads.
XTS influences satellite table loads.
A solution for out-of-sequence data
We have presented a data-driven and dynamic pattern for Data Vault satellite tables to absorb whatever you throw at the Data Vault itself. While out-of-sequence data can be a pain and cause delays, reloads, and erroneous reporting from your data platform, this pattern can certainly help alleviate these problems.
Every out-of-sequence event should be recorded even if it has been corrected so we can use that information to solve technical debt upstream. An incorrect state of a business object may have already been reported on via dashboard or report extract before we could have corrected the timeline. So, it is key that you look to the root cause of your automation issues. In the Data Vault we advocate for pushing technical debt upstream, but realize that some circumstances are unavoidable. XTS provides a dynamic method to absorb that pain.
Until next time!
Additional references:
{kind=link}